12.05
知识库
-
驳回doc解析,只能导入docx
-
测试写报告,多文档一起给到AI,还是会因为注意力稀释,导致“张冠李戴”,BGE 模型会发现两本书里都有“地形”这个词,它还是可能把你不需要的局部文档里写的地形给搜出来
-
写报告知识库一定要隔离开
写报告的设计逻辑
-
全局系统提示词,设定角色——资深工程地质专家、语言风格(严谨、技术术语准确)、引用规范
-
列好详细框架,每个章节自动划分独立Promt模板
-
数据的输入预期: 这个 Prompt 假设用户在库里可能会选中几篇 PDF(比如《区域地质报告》、《测量图说明》),然后输入这个 Prompt。AI 会根据这些选中的文档内容,填充进这个框架里。
-
“动态调整策略”前置,这是为了解决你最担心的问题。我用了
Critical Instruction(关键指令)来强调这一点。告诉 AI,“没有海就不写海”,“有冰川就加冰川”。这是为了防止 AI 像填空题一样,明明是内陆项目还硬造一个“海底地貌”出来。 -
参考提纲的“软化”: 在提纲部分,我使用了“尝试覆盖”、“视项目情况选写”等词汇,给 AI 留出了逻辑判断的空间,而不是命令它必须逐条执行。
-
模仿语气,给出Example,比如某一段 写好的“地形地貌”,让他模仿
切片优化
- 如果要写某个项目的报告,不要把几百页文档上传解析。不止依赖程序本身的分段,可以利用二次AI分段或者手段分段方式能够把针对性数据提取出来,多个文档但是总字数少,让分段更精准
12.12
linux20服务器部署
-
在docker跑vLLM镜像,加载了千问3 8B模型,显存卸不掉,然后重启后奔溃了
-
使用: FastAPI + transformers 库直接加载BGE模型
-
使用python脚本制定了open api兼容格式
学习其他rag的进阶框架
因为之前的框架还是偶尔会出现掉知识库问题,还有测试未来趋势 agent模式
部署了一个目前相对更全面的框架
-
更好的数据切片方式,不按字符切片后提取文本,而是使用YOLO这种小模型识别布局
-
看的话,就能避免原来文本流像多排表格,页眉页脚等错乱
-
看的话,更能理解出这是标题,还是注释,保留文档结构语义,比如这是正文,表格,复杂结构的表,中间有分割线,先读左再读右
-
这个新增了混合检索,如关键字检索,向量搜索
-
目前没有出现太大幻觉以及掉知识库
尝试使用Agentic RAG
-
搭建一个智能体知识库
-
智能体,是多了工具(MCP)和自主决策(另一个批判性LLM),目前只接入了自主决策(3轮反思能力)
-
还没有研究明白,目前效果一般,mcp也没有接入
12.19
知识库完善
-
新增账号管理,可以注册自己的账号。管理员可以管理普通账号
-
子账号沿用统一的管理员账号模型配置
-
新增独立知识库,不同账号是各自的知识库,各自得聊天会话,统一由各自账号管理
-
新增知识库文档编写目录,点击目录可以根据知识库写对应章节的
召回率测试
- 测试发现严重问题,如果知识库数据不全,但是提示词模板太全,AI回去填空,会瞎编乱造
- 大而全”的固定提纲,反而出现的全是幻觉
- 约束太严格,会导致说话信息太少,不敢说
- 得讲究平衡
12.26
学习测试MCP
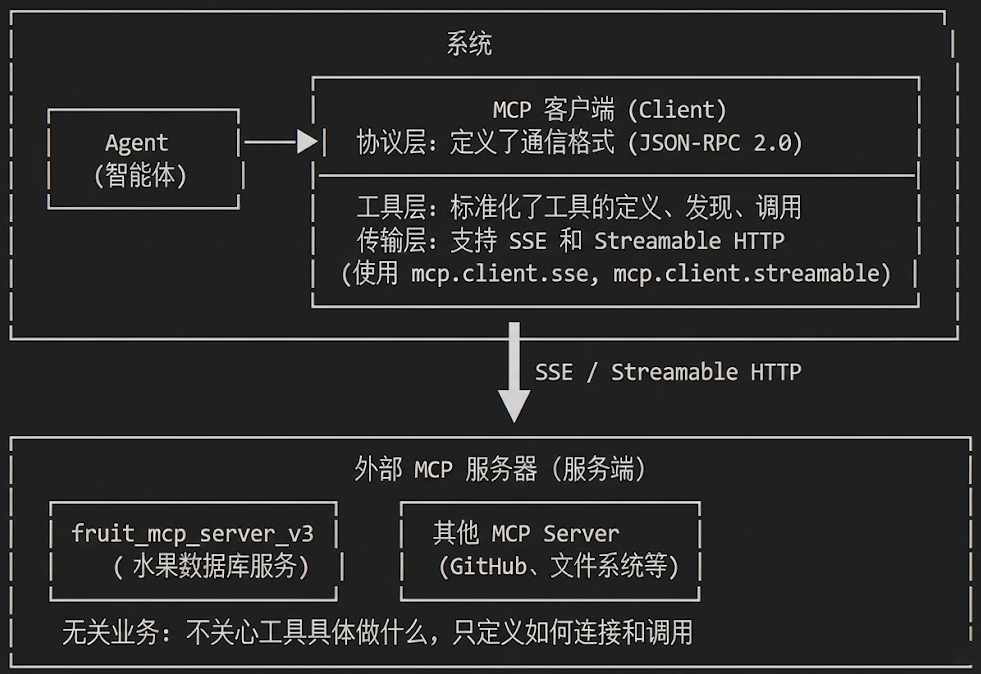
- 接入了一个抓去解析网页内容的mcp
- 接入了一个搜索互联网关键字的mcp
- 学习了一下数据库,简单弄了一个数据库文件
- 接入数据库搜索mcp
发现之前遇到的不准确问题
-
docker开发时候,服务有点多,缓存有点多,经常因为缓存导致开发的代码没有生效或者沿用了旧历史数据,影响判断。解决办法重启电脑。还得看下是哪个服务影响了缓存
-
AI大模型上下文混淆问题,解决办法给提示词:“每次回复都忽略之前的任务”,缓存也会影响上下文,导致回复效果不好