训练集
1.搜集图片
- 引擎搜索,有版权和无版权的图库外,
- 还有可以造图片,真实的物体拍照,或者模型拍照
- AI造图,然后在变为训练集素材
-
训练集应当能尽量涵盖训练对象的“多样化样本’,多个工程项目纹理贴图、纹理网站图,地质岩性专用纹理,地质岩石图处理后成为纹理
-
纹理一定是纯纹理图,不包含不包含三维信息的空间方位、透视、光影或物体轮廓等信息,他们应该只反应材质表面的颜色和细节,
-
训练集数据的正则化图像,用于避免图像过拟合的方式,可以不填
-
训练集增强学习
-
动漫二次元风格20-30张
-
3个文件夹,image、log、models
-
image下在创建,6_NingGuang ,6代表重复次数,repeat,预处理的一部分,创建了一个虚拟数据集,比如这个文件夹有5张照片,那么在与处理后实际加载这个文件夹下,也就是总虚拟数据集有30张。文件夹图片由5张——>30张;Epoch它定义了训练过程中这个虚拟数据集被完整遍历的次数 ;NingGuang代表概念,一般是触发词
-
可以新建不同概念文件夹,存放不同训练集图片植入多个概念
-
二次元图片建议设置重复次数在5-10,三次元10-30
2. 裁剪
- 如果不裁剪,他会自动识别分辨率,按照差不多相同比例的图,统一为近似分辨率,整理出很多桶,bucket,每个bucket代表一种分辨率图片的集合

- 太多的的桶可能也会影响训练的质量和速度,应裁剪更多标准分辨率的图片
- 质量处理,如果繁杂元素太多,并且训练需求很专一,就是一个物品,就可以抠出来
3.打标
-
WD1.4打标器,附加标签,字词,作为训练主体触发词,排到第一位
-
打标反推不是词越多越好,也不是越准确越好,应该是越希望AI学习的东西,越不能出现在标注里

-
如果标记打的特别全,那每次要出效果,必须要把白头发、红眼睛两个词一起写进去才能出来对应效果,如果不写,AI就会画没有白头发和红眼睛的这张图片
-
所以应该对标签进行清洗和修正,使用 Dataset Tag Editor的插件,加载数据集路径,右侧列举了所有标签,然后去点击过滤对应不要的标签
-
为了降低学习难度,尽可能详细的语言描述产品本身具备的一些特征,如果是扣了图的,一定要加上白色背景这样的词
-
打乱标记,使得提示词也乱的,否则可能会越靠前的提示词潜在的重要性越高,多轮训练可能会让ai太过侧重靠前的词的概念;但是触发词还是重要的,保持n=1个标签不变,其他打乱顺序
整体审核
- 批量删除txt打标文件的错词
- 批量删除和本体有密切相关的词
- 如果想要统一某一个特征,就把这个词也删掉。如想要服饰也一模一样,就要把衣服的词也删掉
- 相反,如果偶尔想要这个特征,在训练时候就要加上这个词,并且把这个词记录下来,想要这个特征就提示词加上
批量调整
- 一些共通有明确特质、元素的图片,为它批量去增加一些标签;比如照片偏暗,说明有一些照片偏暗,就需要针对这些偏暗照片,对他们的txt标签进行增加一些特质标签,如:night、dark
- 工具使用选择过滤器
单张审核
- 有一些图在tagger识别不出来的,比如发光的粒子、花、树、建筑等,这个时候需要补全
- 思路是,看到这张图,如要自己要画出来,都要画哪些元素,然后去和tagger的词对比,然后补充
训练参数
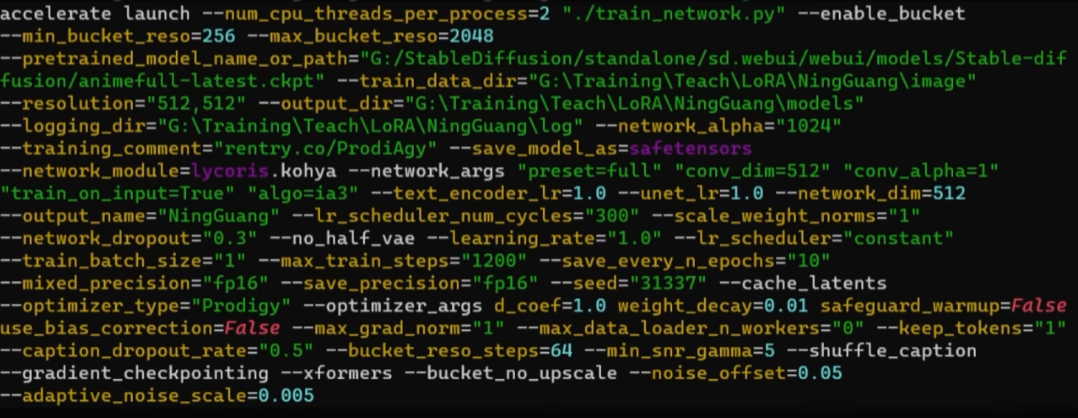
- 读取图片,进行转化为张量 ,转化为嵌入向量
- 有直接预设的参数 iA3-Prodigy-sd15
1. LoRA Type :
LyCORIS,LoRA除常规方法外的其他秩自适应实现

-
LoHa、LoKr更擅长训练画风且面对多概念,训练更有优势,单一训练集
-
底模选取,texture diffusion或者SD1.5底模
2. 训练步长,Training Steps,
-
如果batch为1,那么一个Epoch训练后,30张图片,需要进行30步训练
-
如果batch为5,马额一个epoch,步数就是 30/5=6步
-
如果最大训练步长有100,那么达到100步后,就停止训练了,就算epoch没有循环完
-
步长就是训练过程中模型参数更新的次数,每次更新通常对应于处理一个批次(batch)的图片,并根据损失函数进行一次梯度下降。
-
图片多,风格迁移类,repeat数就低一些
-
训练集规模在20-30张,训练步数1200-1500
-
最大训练步长:假如采用梯度下降算法来更新模型参数,当设置了最大训练步长时,步长不会超过这个最大值。要是步长过大,模型参数更新的幅度就会很大,这可能致使模型在最优解附近来回跳动,无法收敛,甚至会使损失函数值不断增大,导致模型发散。所以,设定最大训练步长可以避免这种情况的发生。步长太小,参数更新的幅度会很小,模型收敛的速度会变得很慢,需要更多的迭代次数才能达到较好的效果,这会消耗大量的计算资源和时间。
-
批次大小,如果同时学习多张不同图片,每张图片的调优精度会下降,但由于学习的是综合捕捉多张图片的特征,最终结果可能会更好。但是批次越大学习时间越少,调谐精度会降低,权重变化的次数也会减少,因此在某些情况下,学习可能会不足
-
批次增加,相同10个Epoch,步数就减少了一倍,但实际上学习的图片张数也翻了2倍,所以立项的学习步数可能也会相应下降
起锅时间=步长,学习率是做菜的火候,学习率太高会糊
3. 学习率,
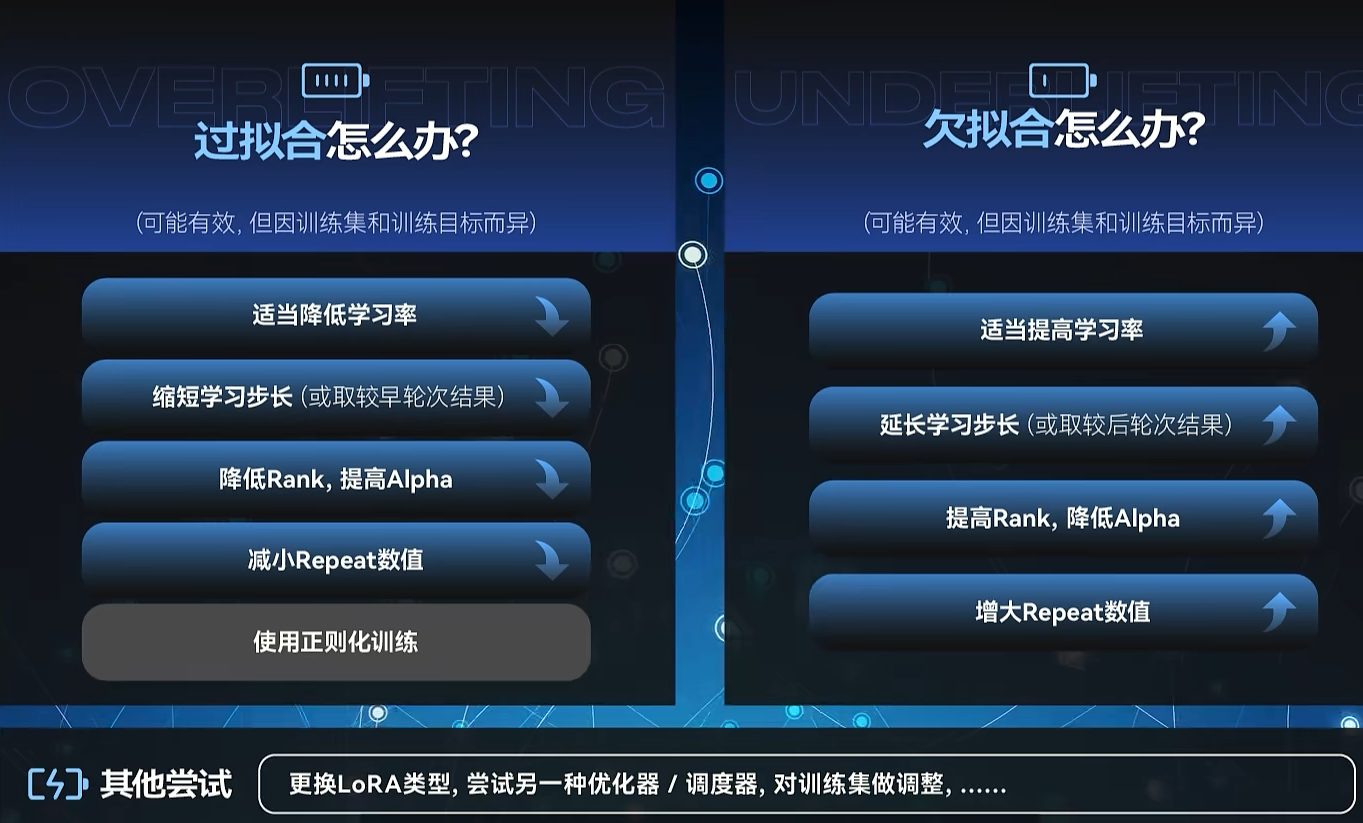
- 学习率越高,学的会更多,但是过拟合后,可能会把不该学的,也学进去。如背景,北京的小装饰、画风、色调全都学会,这样千篇一律
- 欠拟合,一般概率小于前者,因为训练很容易过拟合
- 学习率偏高,可能很短的步长上就可以出效果,相反也是
- 默认学习率,0.0001比较合适
- 越大的批次需要越大的学习率,当批次增大到原来的2倍,学习率增到到原来的根号2倍;但是除非batch size的变化达到十几倍以上,不然没有特别必要去调整lr
- 文本编码器对学习率的敏感程度远高于噪声预测期(U-Net),一般TE(Texture Encoder)设置为为U-Net的二分之一到十分之一。U-net学习率一般就等于上面说的学习率,如果填了U-Net学习率,上面的学习率就不生效了,因为默认TE学习率就是二分之一U-Net学习率
- 训练集图片增加,应尝试降低学习率,训练样本的增加可能导致梯度下降算法在更新模型参数时需要更小的步长,因为更多的数据可能意味着更复杂的损失曲面。如果学习率过大,可能会导致训练不稳定或者错过收敛点。因此,一般会采取降低学习率的措施,或者开始就使用一个较低的学习率,逐渐增加直到能找到一个表现得更好的学习率数值。
4. 优化器 Optimizer
- 决定了在这个过程中把控学习的方式,直接影响学习效果
- 默认常用AdamW8bit,比较适合0.0001学习率
- Lion(谷歌),最佳学习率通常比AdamW小10倍左右,且在大的Batch Size下表现优秀
- Prodigy(三星和Meta),3个学习率都设置为1,他就会在学习过程中自动改变学习率来取得最佳效果
- Cosion调度器,应对大多数场合;cosion with restart,学习率变动曲线,会经过多次重启再衰减来更充分的学习训练集,避免学习过程中的局部最优解,干扰训练,设置学习率周期数3-5次重启次数,如果训练对象复杂,适当增大
5. 网络维度 Network Rank&Alpha
- 作用是搭建一个合适的LoRA模型基底
- NetworkRank(Dimension),值越高,从原始矩阵里抽出来的行列就越多,要微调的数据量就越多,进而能够容纳更复杂的概念,直接影响LoRa模型的大小,最大值为128。在训练一些较为复杂的画风和三次元物品、形象时候,才会推荐128、64高Rank
- 维度太多,会让AI学习很多无关的细节,影响画风
- Locon的Rank一般不超过64,LoHa的不超过32
- Alpha,是用来调节LoRA对原模型影响作用的参数
- alpha和Rank的比值等于使用LoRA时的减弱权重程度
- alpha越接近rank,lora对原模型权重的影响越小,约接近0,lora对权重的微调作用越显著
- 一般是讲alpha设置为rank的一半,或者直接alpha设为1,代表不减弱,完全让微调权重发挥最大作用
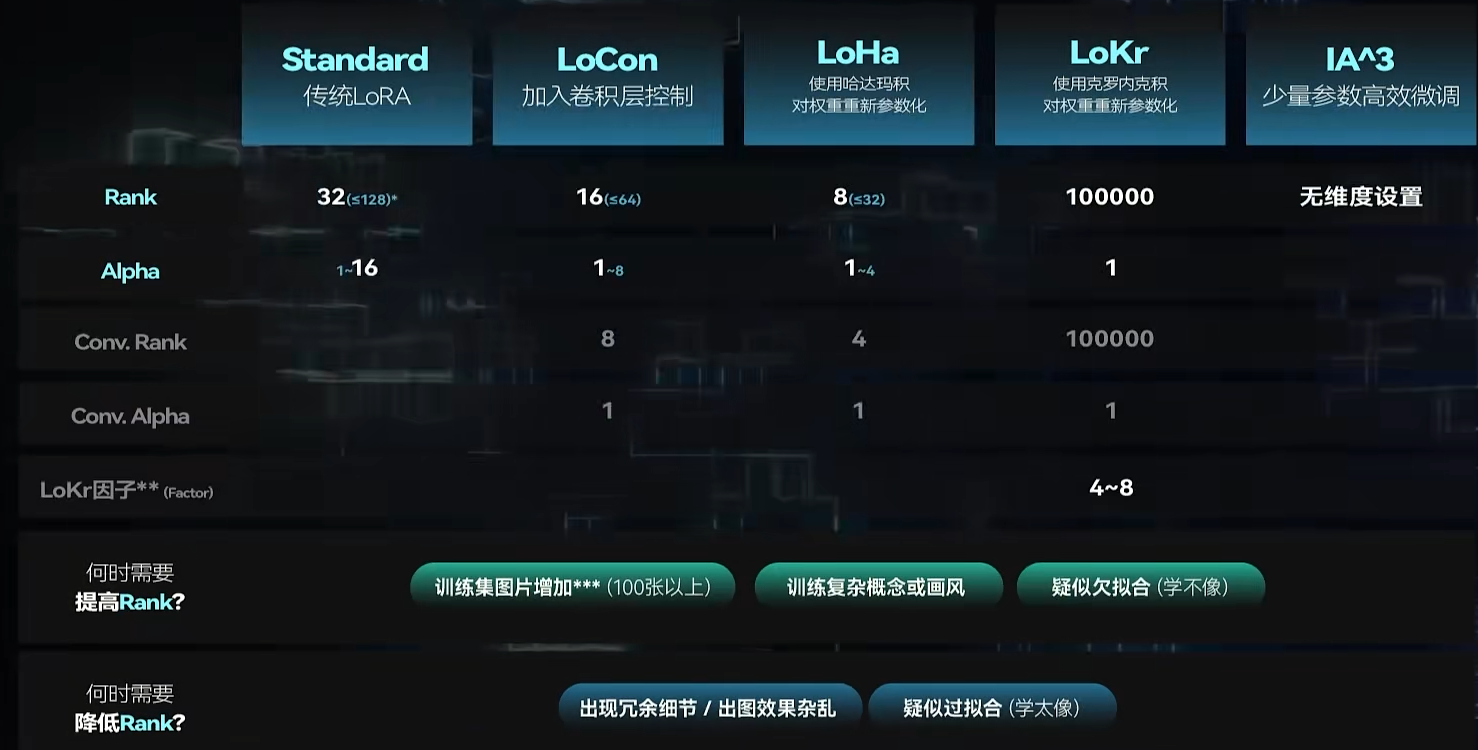 这个图是针对二次元,三次元往上翻一倍
这个图是针对二次元,三次元往上翻一倍
6. 训练性能 Performance
- FP16 FP全程Floating Points,在机器学习里面进行编码存储的数据类型,相比fp32,偷工减料,反而会出现意想不到的情况,而且极大减少计算速度,节约资源
- bfp16更稳定,不过精度没啥变化,选fp16没问题,gtx显卡不支持bf16
- 训练一定会将图片转化为潜空间向量,一般将图片先缓存到潜空间变量(Cache Latent)显存中,然后反复调用
- 交叉注意力,提高模型训练和推理效率,N卡,开启xFormers,可以降低训练过程中的显存需求并显著提高速度,内存高效注意力,会压缩一定量的显存使用,抑制VRAM使用并执行注意力块处理。会慢很多,但是没有足够的VRAM,要打开,低配用户降低爆显存
7.监控训练进程
- 训练的速度,步长度量进程,一次步长的时间有了, 所有训练时间就等于跑完这些全部步长所需的时间,会显示训练一步需要多长时间
- 显示平均损失函数值,loss,loss越低,拟合程度就越高。合适的就是在初期幅度变化比较大,最核在一个相对低位保持震荡(收敛),趋于平稳
- loss值高低没规律,乱飘,说明欠拟合或根本没有拟合
- loss值太固定,只在小数点后三四位小幅度变化,非常大的概率过拟合了
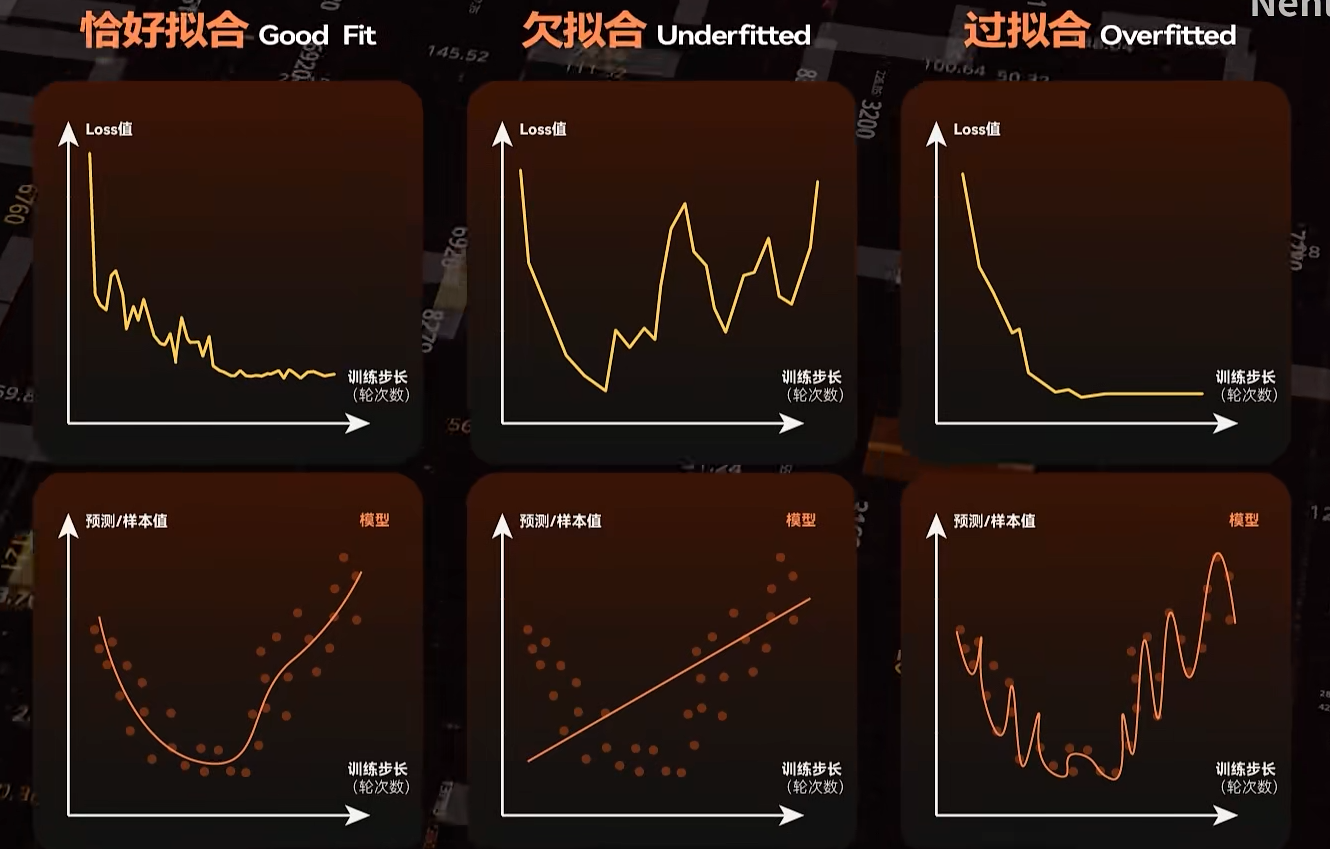
如果loss值不显示了,说明有一些参数被误调到了极端大或者小的值,通常是学习率
-
TensorBoard:训练过程中各项参数变化的可视化工具
-
LoRA关注第一个是平均损失值,第二是 文本编码器学习率,噪声预测器(U-Net)学习率
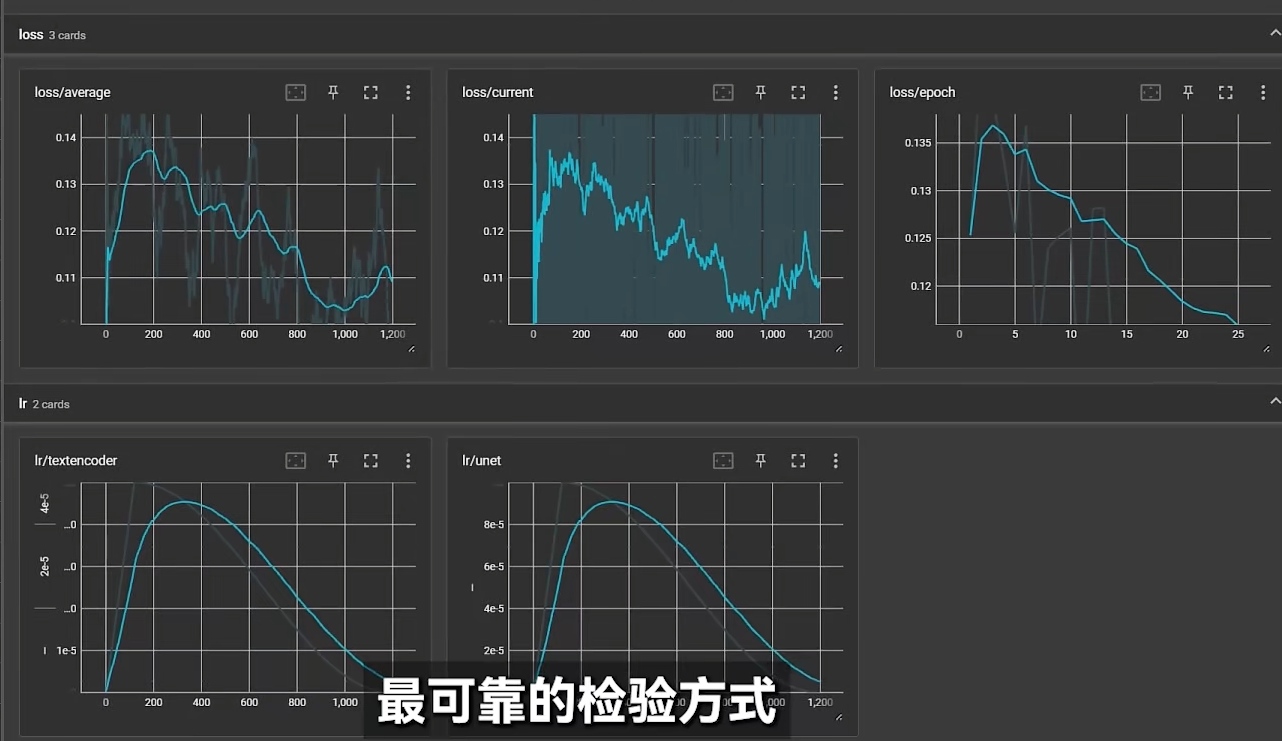
-
每n步采样一次,可以100步查看一次样例,提示词可以用训练集倒推出来的提示词当做适当改动
-
最大步数后每隔多少回保存一个模型,最终的loRA可以效果可能不行,而一些中间段的lora反而表现会更好,因为最终的可能已经过拟合了
-
使用xyz图标,把模型都加载进去查看不同阶段模型出图效果
专利涉及的其他的
-
这些图片应该是纯纹理图像,不包含空间方位、透视、光影或物体轮廓等信息。它们应该只反映材质表面的颜色和细节
-
描述材质表面的视觉特性(颜色、粗糙度、图案等)。
-
只关注平面的、重复的表面细节,不包含三维信息。
-
准备底模和训练集:
- 底模是一个预训练模型(比如Stable Diffusion)。
- 训练集是你准备的小规模数据集(比如几张图片),通常带有标签或描述(caption)。
-
挂载LoRA:
- 在底模的某些层上添加LoRA的低秩矩阵,这些矩阵初始化为随机值。
-
生成图片并对比:
- 用挂载了LoRA的底模生成图片。
- 将生成的图片与训练集中的目标图片(或描述)进行对比,计算损失函数(比如均方误差或CLIP损失)。
-
梯度下降优化:
- 根据损失函数,通过梯度下降更新LoRA的参数(底模的原始权重保持冻结)。
- 目标是让生成的图片越来越接近训练集的特征(比如风格、物体特征等)。
-
迭代训练:
- 重复生成、对比、优化的过程,直到LoRA学会你想要的特征。
地层岩性纹理的特征词汇
以下是我整理和扩充的词汇列表,分门别类列出,方便你理解和使用:
1. 颗粒与结构特征
- 颗粒度(Grain Size):细粒、中粒、粗粒、微粒。
- 晶粒(Crystal Grain):晶体大小、晶形(六边形、立方形等)。
- 碎屑(Clastic):碎屑颗粒、碎屑分布。
- 碎斑(Fragmentation):斑状碎块、碎块大小。
- 粒状(Granular):颗粒感、粒度均匀性。
- 团粒(Aggregate):团块状、聚集体。
- 孔隙(Porosity):孔隙度、空隙分布。
- 分选性(Sorting):颗粒分选好坏(均匀或杂乱)。
2. 形态与纹理样式
- 条带状(Banded):条纹、层状、带状分布。
- 层理(Bedding):水平层理、交错层理、波状层理。
- 脉状(Veined):脉纹、细脉、网脉。
- 斑状(Mottled):斑点、斑驳、杂色分布。
- 块状(Massive):无明显结构的大块状。
- 波纹(Ripple):波状纹、起伏纹。
- 褶皱(Folded):褶曲纹、微褶皱。
- 流纹(Flow Texture):流动状纹理。
3. 破碎与破坏特征
- 破碎程度(Fracturing):裂缝密度、破碎感。
- 粉碎状(Pulverized):粉末状、细碎感。
- 裂隙(Fissured):裂纹、裂缝分布。
- 断裂(Faulted):断层痕迹、错位感。
- 崩解(Disintegrated):崩塌感、松散碎块。
- 糜棱状(Mylonitic):糜棱化、拉伸破碎。
4. 矿物与成分特征
- 矿物成分(Mineral Composition):石英、长石、云母、方解石等。
- 结晶度(Crystallinity):结晶程度(全晶质、半晶质)。
- 矿脉(Veinlets):矿物填充脉、晶脉。
- 包裹体(Inclusion):内含物、杂质颗粒。
- 交代(Replacement):矿物交代纹理。
- 交代斑(Metasomatic Spots):交代形成的斑点。
5. 颜色与视觉特征
- 颜色(Color):灰白、棕红、暗绿、黑色等。
- 色调(Hue):暖调、冷调、单色、多色。
- 变色(Variegated):色彩渐变、杂色。
- 光泽(Luster):哑光、丝光、玻璃光泽。
- 透明度(Transparency):不透明、半透明。
- 晕染(Staining):染色感、渗色。
6. 物理性质与质感
- 外貌致密(Density):致密感、疏松感。
- 坚硬(Hardness):硬度感、脆性。
- 粗糙度(Roughness):表面粗糙、平滑。
- 风化程度(Weathering):风化纹、剥蚀感。
- 韧性(Toughness):韧性感、易碎性。
- 粘性(Cohesiveness):粘结感、松散度。
- 磨蚀(Abrasion):磨损痕迹、磨圆度。
7. 沉积与成因特征
- 沉积纹理(Sedimentary Texture):沉积层、沉积颗粒。
- 化石痕迹(Fossil Imprint):化石残留、生物纹。
- 交错(Cross-bedding):交错层理、倾斜层。
- 冲刷(Erosion):冲刷痕迹、水流纹。
- 堆积(Accumulation):堆积感、堆砌颗粒。
8. 其他地质特征
- 节理(Jointing):节理面、裂隙系统。
- 片理(Foliation):片状结构、薄片感。
- 鳞片状(Scaly):鳞片纹、剥落感。
- 角砾状(Brecciated):角砾感、碎石堆积。
- 熔岩纹(Volcanic Texture):熔岩流纹、气孔感。