架构
Backbone 特征提取网络 → Neck 多尺度特征融合 → Head 检测头 + 分割头
1. Backbone:提取图像特征
前半部分不断卷积、下采样,把原图变成多层特征图。
Conv C3k2 SPPF C2PSA
它学的是:
边缘 纹理 裂缝 颜色变化 块状轮廓 柱状边界 岩芯和箱子的分隔
Conv 普通卷积层遍历图像数据转换高维
C3k2 可以理解成 YOLO 里的高效残差/瓶颈特征模块。
SPPF 是空间金字塔池化,扩大感受野,让模型看到更大范围上下文。
C2PSA 带注意力/特征选择味道,让模型更关注有用区域。
2. Neck:多尺度特征融合
YOLO 不是只看一种分辨率。它会把深层语义特征和浅层细节特征融合。
结构里这些就是 Neck 典型操作:
Upsample Concat C3k2
目的:
深层特征:知道“这大概是什么” 浅层特征:保留“边界在哪里” 融合后:既识别类别,又定位细节
这对岩芯很重要,因为大块碎块、细长柱状、牌子大小差异很大。
3. Head:输出结果
最后是:
Segment26
这是 YOLO26 的实例分割头。它会同时输出:
检测框 bbox 类别 class 置信度 confidence mask 系数 / mask 原型
YOLO 分割头通常不是像 U-Net 那样直接给整张图每个像素分类,而是类似:
生成一组 mask prototypes 每个实例预测一组 mask coefficients coefficients 组合 prototypes 得到该实例 mask
所以它能区分多个同类实例,比如一堆柱状岩芯每一段分别一个 mask。
和 U-Net 的核心区别
U-Net 更像:
输入图 -> 编码器 -> 解码器 -> 每个像素属于哪一类
常见输出是语义分割:
这片像素是柱状 这片像素是碎块状
YOLO segmentation 更像:
输入图 -> 多尺度特征 -> 找出每个对象 -> 给每个对象一个 mask
输出是实例分割:
第 1 段柱状岩芯 mask 第 2 段柱状岩芯 mask 第 3 个碎块 mask
图片预处理
尺寸
-
在利用 GPU 矩阵加速训练时,一个 Batch(比如一次性塞入 16 张图)里的所有图片,必须被打包成一个长宽高完全一致的四维张量(Tensor)。如果图有长有短,GPU 的硬件架构无法在同一个线程块里进行对齐计算。
-
为了标准化,学术界和官方代码默认都把尺寸统一缩放并补齐为正方形(如 或 )。
如果图大部分是长图,可以开启矩阵训练,rect=True
具体原理:当开启 rect=True 后,YOLO 的数据加载器会在训练前,把数据集中长宽比类似的长图编排在一个 Batch 里。它不再死板地把它们补齐成 的正方形,而是自适应地补齐到最接近的、符合 32 倍数的矩形(例如 )
相比长图训练集非要弄成方图,好处:
- 显存暴省:去掉了大量的无用灰色填充像素,可以把显卡(如 4090)的
batch设得更大。 - 速度飙升:网络不再对无用的背景死磕卷积,训练和推理速度会明显加快。
- 精度提升:模型不需要分出精力去识别那些人造的灰色边缘,能够更加聚焦在长条状岩心的连续特征上。
参数
核心参数判断
1. 字母的含义
-
(B) 代表 Box:针对矩形目标检测框的评估,目标检测框(Bounding Box),考核矩形框定位
-
(M) 代表 Mask(掩膜):针对像素级实例分割掩膜的评估,代表这是针对像素级分割轮廓定位准确度的评估,而不是外面那个矩形框的评估。
2. 左侧的各种 Loss(损失函数)
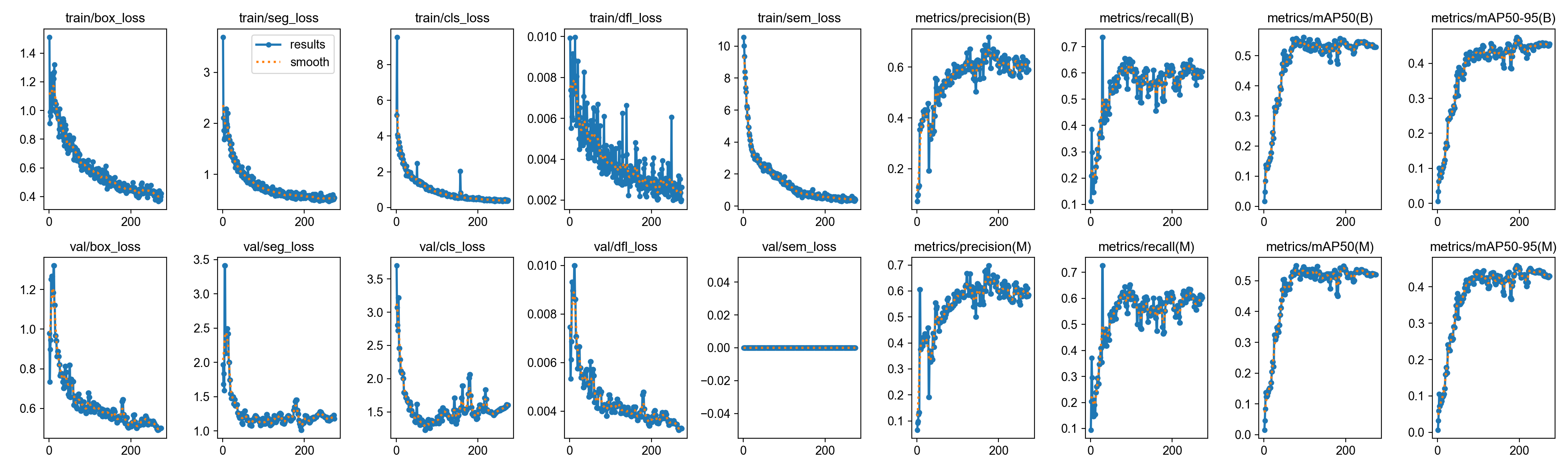
损失函数用来衡量预测值与真实值之间的差距,曲线持续平稳下降代表网络在正常收敛。
box_loss(检测框边界损失):- 解释:衡量预测的矩形框和真实矩形框的重合程度(通常使用 CIoU 或 GIoU 算法)。
- 工业含义:如果该值居高不下,说明模型定位岩心位置不准,框画得太松或太紧。
seg_loss(分割掩膜损失):- 解释:衡量预测的像素级 Mask 和真实像素边缘的差异(通常使用二元交叉熵 BCELoss)。
- 工业含义:核心指标。数值越低,说明模型对岩心边缘、破碎程度的扣图越精细。
cls_loss(类别分类损失):- 解释:衡量目标类别分类的准确性。
- 工业含义:如果分类错误(如把“破碎岩心”认成“完整岩心”),该 Loss 会飙升。
dfl_loss(分布焦距损失 - Distribution Focal Loss):- 解释:YOLOv8/v11 等网络特有的参数,用于回归更加精细的边界框边缘,把边界框的位置当作一个概率分布来预测。
- 工业含义:辅助提升检测框在模糊或重叠边缘的定位精度。
sem_loss(辅助语义分割损失):- 解释:部分多任务或自定义多头网络中引入的全局语义分割损失,用于提升背景与前景的整体区分度。 Loss 代表模型的误差,曲线从左往右一路向下并逐渐平稳,说明模型在正常学习。
如果 val 的 Loss 在后半段突然不降反升,说明模型“过拟合”了(死记硬背训练集,泛化能力变差)。 从你的图来看,收敛非常漂亮,没有明显的过拟合。
3. 右侧的 Metrics(评估指标)
指标用于评价模型在实际考试(验证集)中的得分,数值通常在 0~1 之间。
-
precision(精确率 / 查准率):- 通俗解释:模型预测出的所有目标里,有多少是真正猜对的?(宁缺毋滥)。
- 计算公式:(真正例 / 所有预测为正例的数量)。
-
recall(召回率 / 查全率):- 通俗解释:原本存在的真实目标分类里,模型成功找出了多少?(宁错杀不放过)。
- 计算公式:(真正例 / 所有真实标签的数量)。
-
mAP50(宽松平均精度):-
解释:IoU 阈值设为 0.5 时的平均精度(Mean Average Precision)。
-
特点:只要模型预测的 Mask 与真实 Mask 的交并比(IoU)大于或等于 50%,该预测就被判定为“正确(True Positive)”。它主要考核模型“有没有找对地方”、“轮廓大致对不对”,对边缘分割得是否丝毫不差要求不高。他是判断业务初期、快速验证模型是否收敛。
-
-
mAP50-95(严格综合平均精度):- 解释:在 IoU 从 0.5 到 0.95(步长 0.05)的 10 个阈值下的 mAP 平均值。
- 计算方式:它是以下 10 个特定阈值下 mAP 的数学平均数:
- 特点:这是一个非常严苛且全面的指标(也是 COCO 数据集官方最看重的标准)。
- 如果模型只能做到“大致框对”(IoU在0.5左右),那么在 IoU 设定为 0.85、0.90、0.95 这些高精度要求下,模型的得分就会非常低,从而拉低整体的
mAP50-95。 - 只有当模型的边缘分割得极其精准、与真实贴合度极高时,这个指标才会好看。他是最终模型评估、论文对比、对边缘精度要求极高的工业场景。
IoU(Intersection over Union,交并比)
-
衡量“模型预测的 Mask”与“真实标签的 Mask”重合程度的指标。
-
。IoU 越接近 1,说明分割得越精准。 指标代表准确度,曲线从左往右一路上扬,说明模型越来越聪明。
精度曲线
用于写报告或深度调优
1.混淆矩阵(Confusion Matrix)—— 诊断模型的“指鹿为马”
原理分析
混淆矩阵的作用:它就是那张被圈出所有错题的卷子。它不仅告诉你模型“做错了几道题”,更关键的是告诉“模型把正确答案错写成了什么”。
- 横轴(True):代表真实标签
- 纵轴(Predicted):代表模型预测标签 对角线颜色越深、数字越大越好;非对角线区域有数字,代表发生了误判。
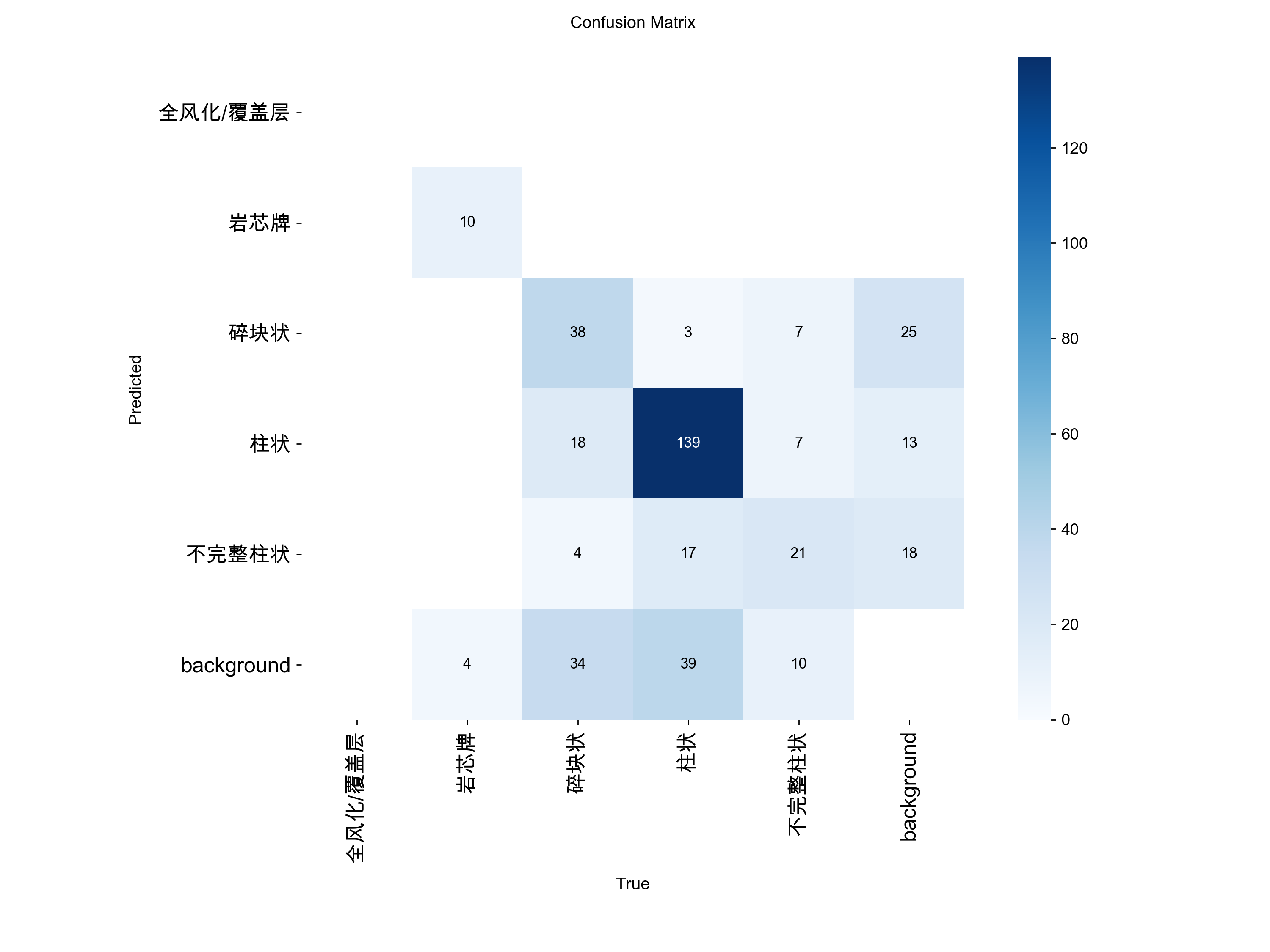
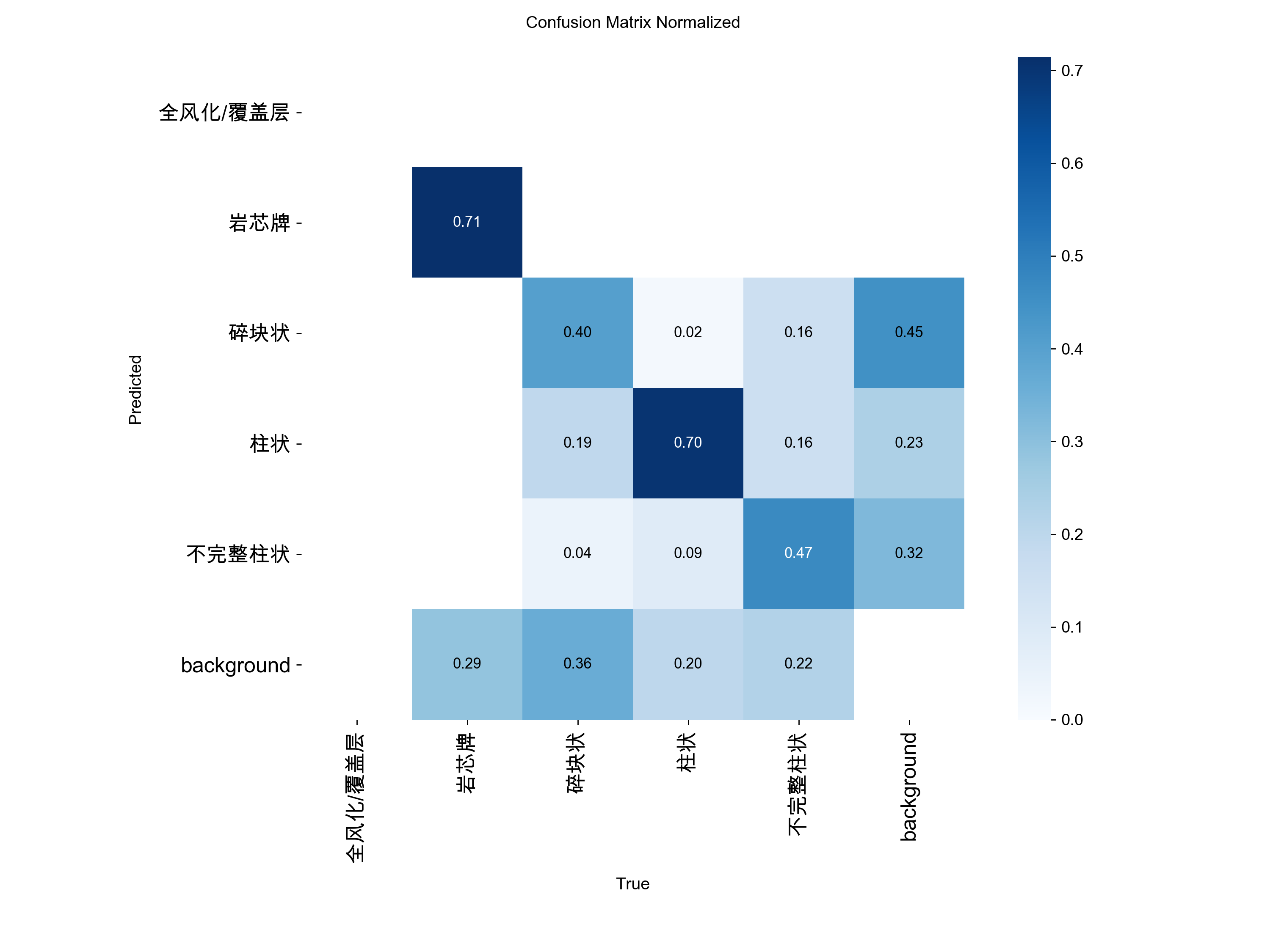
-
落在对角线上(最完美): 横轴是“柱状”,纵轴也是“柱状”,两者一碰,数字加 1。这就叫“预测正确”。所以,对角线颜色越深、数值越大,说明模型基本功越扎实。
-
落在对角线之外的格子里(指鹿为马): 横轴是“不完整柱状”(标准答案),纵轴却对齐到了“碎块状”(AI 预测)。这就说明模型发生混淆了。
-
落在 background(背景)行/列里(最致命):
-
True 是岩心,Predicted 是 background:说明这里明明有块岩心,模型却啥也没看到。这叫漏检(False Negative)。
-
True 是 background,Predicted 是岩心:说明这里原本是空箱子或背景,模型却幻觉出了一块岩心。这叫虚警/误检(False Positive)。
-
目前这张图,柱状70%成功率,岩芯牌百分之71%成功率,其他很低,但是不完整柱、碎块本来标注也有重叠问题
调优指导
场景 A:两个类别之间疯狂“互混”
-
现象:在非对角线的某个格子里,数值异常的大(比如你的图中:真实是碎块状,有19%被认成柱状;真实是不完整柱状,有16%被认成碎块)。
-
病因分析:模型没有瞎猜,它知道这里有东西,但是它分不清这两个类别的临界特征(比如断口到什么程度算不完整,碎到什么程度算碎块)。
-
💡 具体的调优指导动作:
-
数据清洗(检查人类自己):往往是因为打标签的人标准不统一。第一步应该去检查数据集,是不是自己或者标注员在标注时,就把一些模糊的碎块错标成了不完整柱状。
-
局部特征增强(改数据增强策略):在 YOLO 的训练配置(如
default.yaml)中,引入或调大mosaic(马赛克增强)、mixup算法,或者使用剪裁(Crop)策略,专门强迫模型去凑近了看局部纹理,而不是看大体轮廓。 -
修改业务分类逻辑(改架构/标签):如果在岩土工程业务上,“不完整柱状”和“碎块状”即使分错了也不影响大局,最有效的办法是在数据层面把这两个类别合并为一个大类,模型整体的 mAP 会瞬间暴涨。
-
场景 B:大面积的目标被归为 background
-
现象:矩阵的最后一行(或最后一列)有大量数字,很多真实的岩心分类最后都流失到了 background 里(比如你的图里,碎块状有 36% 变成了背景)。
-
病因分析:模型压根没觉得这里有个目标。可能是目标太小、颜色跟背景太像,或者模型极其不自信。
-
💡 具体的调优指导动作:
-
增加负样本(Background Images):往训练集里扔一些纯背景、不打任何标签的岩心箱空图。YOLO 看到这些图后,会深刻记住“没有岩心的地方长这样”,从而反向提升对弱小、破碎岩心的敏感度。
-
调大输入分辨率或更换大模型(改训练命令/改结构):你已经开启了 1280 分辨率,如果碎块依然漏检严重,说明
yolov26s这个“小骨架”网络(s号)在下采样过程中,把小碎块的特征像素直接给“弄丢(蒸发)”了。此时必须停止使用 s 号模型,升级到 m(Medium)或 l(Large)号网络,用更深的特征提取网络保住微小像素。 -
调整损失函数权重(改源码/配置):在 YOLO 内部,可以手动调大
box或cls的损失权重(Loss Gain),告诉网络:“如果漏检了目标,惩罚加倍”,逼迫网络宁可多猜,也不能漏猜。
-
场景 C:某行/某列完全是空白
-
现象:比如你的图中,【全风化/覆盖层】这一行一列直接蒸发了。
-
病因分析:这是低级的数据集管理错误。
-
💡 具体的调优指导动作:
- 去检查你的代码和划分脚本(
train/val划分)。通常是因为该类别总样本太少,在随机划分验证集时,验证集里刚好一个该类别的样本都没分到。导致模型在验证阶段根本没有该类别的“标准答案”去参与矩阵计算。
- 去检查你的代码和划分脚本(
2.PR 曲线(Precision-Recall Curve)—— 评定各类别真实战斗力
- Precision(精准率):AI 认为是的物体里,有多少是真的?(考核:抓得准不准,防作假)。
- Recall(召回率):真实存在的物体里,AI 抓到了多少?(考核:找得全不全,防漏检)。
痛点
-
如果你要求 AI 必须“绝对精准(Precision 100%)”,AI 就会变得极其胆小,它只敢框出那一块轮廓最完美的、100% 有把握的【柱状岩心】,其他稍微有点模糊的全部放弃。结果:准是极准,但漏检了一大堆,Recall 瞬间跌入谷底。
-
如果你要求 AI 必须“一个不漏(Recall 100%)”,AI 就会变得极其激进,宁错杀不放过,把箱子边缘、泥土甚至阴影全部框成岩心。结果:全是一网打尽了,但里面混了一堆垃圾,Precision 瞬间暴跌。
必须有一个图,能把模型在“从最胆小到最胆大”的所有状态下的表现全部画出来,这就是 PR 曲线。有一个平衡标准值就是置信度阈值(confidence)
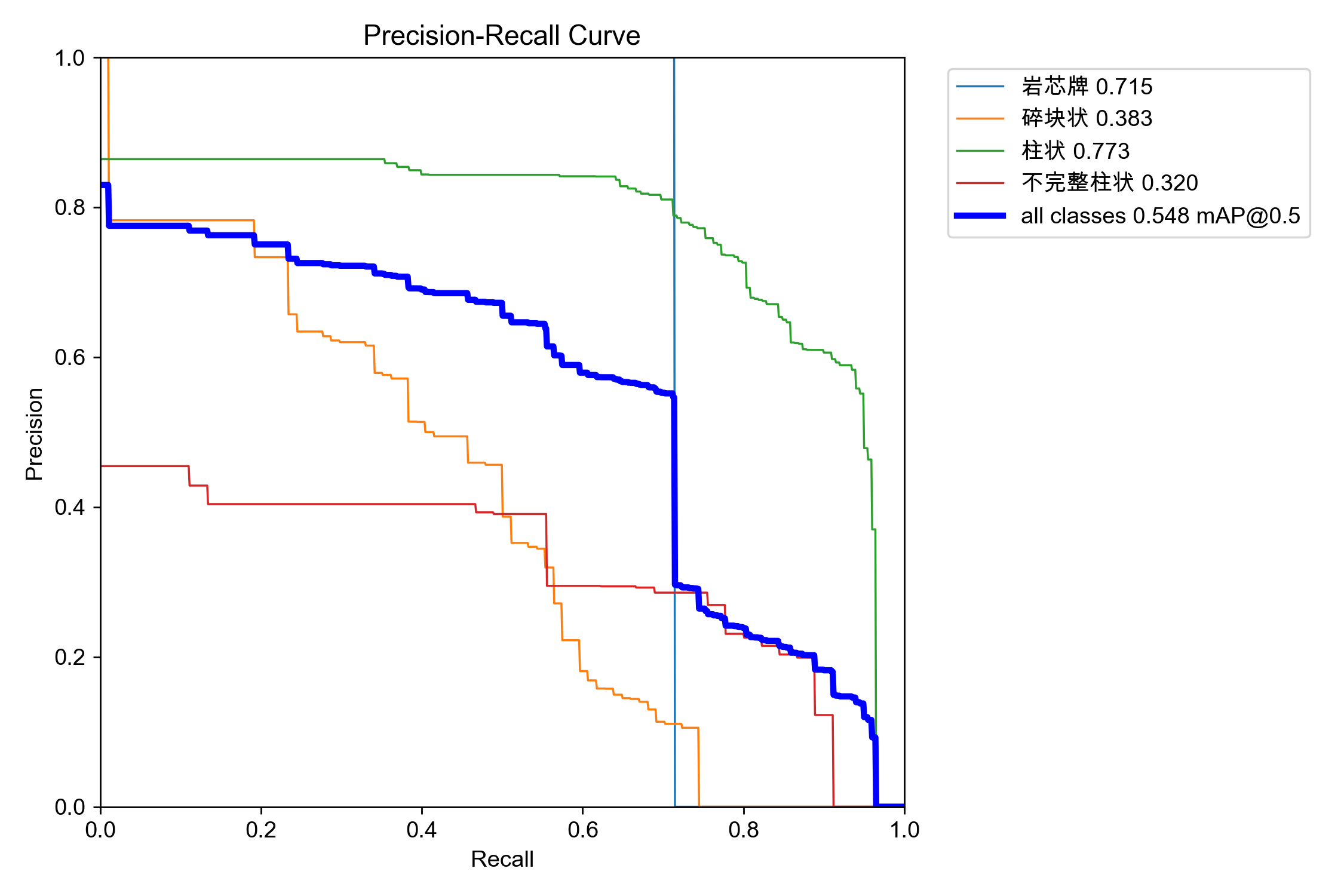
- 横轴(X轴):Recall(召回率,从 0 到 1)。
- 纵轴(Y轴):Precision(精确率,从 0 到 1)。 图的右上角坐标 (1.0, 1.0) 是深度学习的“天堂”。如果一条曲线能死死贴着最顶端和最右端,形成一个正方形,说明这个模型无敌了:既抓得全,又抓得准。
怎么判断类别性能强弱
- AP(Average Precision):单条曲线下方的围成面积。面积越大(越往右上靠),说明这个类别的性能越强。
- mAP(Mean Average Precision):所有类别的曲线面积算一个数学平均数。图里
all classes 0.548 mAP@0.5,就是把岩芯牌、柱状等所有线的面积加起来除以类别数。
深度调优指导
调优核心手段 1:对比 Box PR 和 Mask PR —— 诊断网络的“瓶颈在头还是在身体”
-
你的数据现状:
BoxPR_curve.png的均值是 0.552MaskPR_curve.png的均值是 0.548
-
具体的调优指导动作: 这两条曲线的形状、走势、甚至最终的面积几乎一模一样(只差了 0.004)。这是一个极其关键的信号:说明限制你模型升分的瓶颈,根本不在最后的“Mask分割头”上,而在前面的“特征提取网络(Backbone)”或“检测头(Box Head)”上。
-
错误的操作:去魔改、去调大损失函数里的
seg_gain(分割损失权重),或者换更复杂的分割解码器。这些都是无用功。 -
正确的调优:应该把精力全部放在如何让网络“认出物体”上。比如更换更大号的 Backbone(从 s 升级到 m),或者调整
box_gain、cls_gain的比例。只要 Box 指标上去了,Mask 指标会自然而然地被带上去。
-
调优核心手段 2:观察曲线的“悬崖式下跌”点 —— 诊断数据增强的烈度
-
你的数据现状:
- 看【碎块状】(橘色线)和【不完整柱状】(红色线),它们在 Recall 处于 0.1~0.2 的极低水平时,Precision 就已经非常低了(红线一上来就只有 0.45 左右),并且随着 Recall 往右走,曲线呈现阶梯状或剧烈震荡向下滑落。
-
💡 具体的调优指导动作: 这种一上来就上不去的曲线,说明模型对这两个类别的基本特征处于懵圈状态。稍微想多抓一个碎块(Recall向右移动),就会带进来数倍的误检(Precision垂直坠落)。
-
针对性调优动作:
-
引入 Copy-Paste(复制粘贴)数据增强:YOLO 支持
copy_paste参数。你可以手动在配置中开启它。它的作用是把训练集里的【碎块状】和【不完整柱状】像素抠出来,随机粘贴到其他正常的岩心箱图片上。这能强制增加难样本的曝光率,扩充样本边界,把这条低迷的曲线往右上角生生推上去。 -
局部重采样(Class-Aware Sampling):在数据加载器(Dataloader)里,让包含碎块和不完整柱状的图片有更高的概率被网络抽到,进行重复学习。
-
-
调优核心手段 3:各类别面积差距过大 —— 诊断“长短脚”现象
-
你的数据现状:
- 【柱状】拿到了 0.774,而【不完整柱状】只有 0.320。最高和最低差了快一倍。
-
💡 具体的调优指导动作: 如果一个模型的总分是被某一两个极其优秀的类别撑起来的,而在实际生产中各类别同等重要,这就叫“严重的类别不平衡”。
- 正确的调优:此时绝对不要再盲目增加整体数据量了。如果你这时候再去现场拍 100 张常规的岩心照加进数据集,由于常规照里往往【柱状】最多,结果只会让【柱状】的曲线更完美,而【不完整柱状】的曲线由于稀释变得更差,总分反而停滞不前。你应该开启定向数据采集,后面只拍、只标含有大量碎块和不完整柱状的“烂岩心”,直到这两条弱势曲线的面积逼近 0.5~0.6 产生木桶效应为止。
3. F1-置信度曲线(F1-Confidence Curve)—— 决定模型部署的黄金阈值
results = model.predict(source="岩心图像.jpg", conf=0.25)
这个 conf(Confidence,置信度阈值)就是 AI 的胆量。AI 判定一个物体是岩心后,会给自己打个分(比如:我有 60% 的把握它是柱状岩心)。
-
如果把代码里的
conf设得太高(比如0.5),AI 就会变得极其保守,只有把握大于 50% 的才敢框出来。结果:Precision(精准率)上去了,但漏检一网打尽,Recall(召回率)暴跌。 -
如果把代码里的
conf设得太低(比如0.1),AI 就会变得极其激进,哪怕只有 10% 的把握也敢画框。结果:Recall 上去了,但错把泥土当岩心,Precision 暴跌。
为了解决这个矛盾,数学家发明了 F1-Score(F1分数)。它是把 Precision 和 Recall 强行揉在一起算出的一个综合得分(调和平均数):
F1-Score 越高,说明两者的平衡越完美。而 F1-Confidence 曲线,就是把模型在 conf 从 0.0 一直变到 1.0 的整个过程中,所有类别的 F1 得分全部画出来。
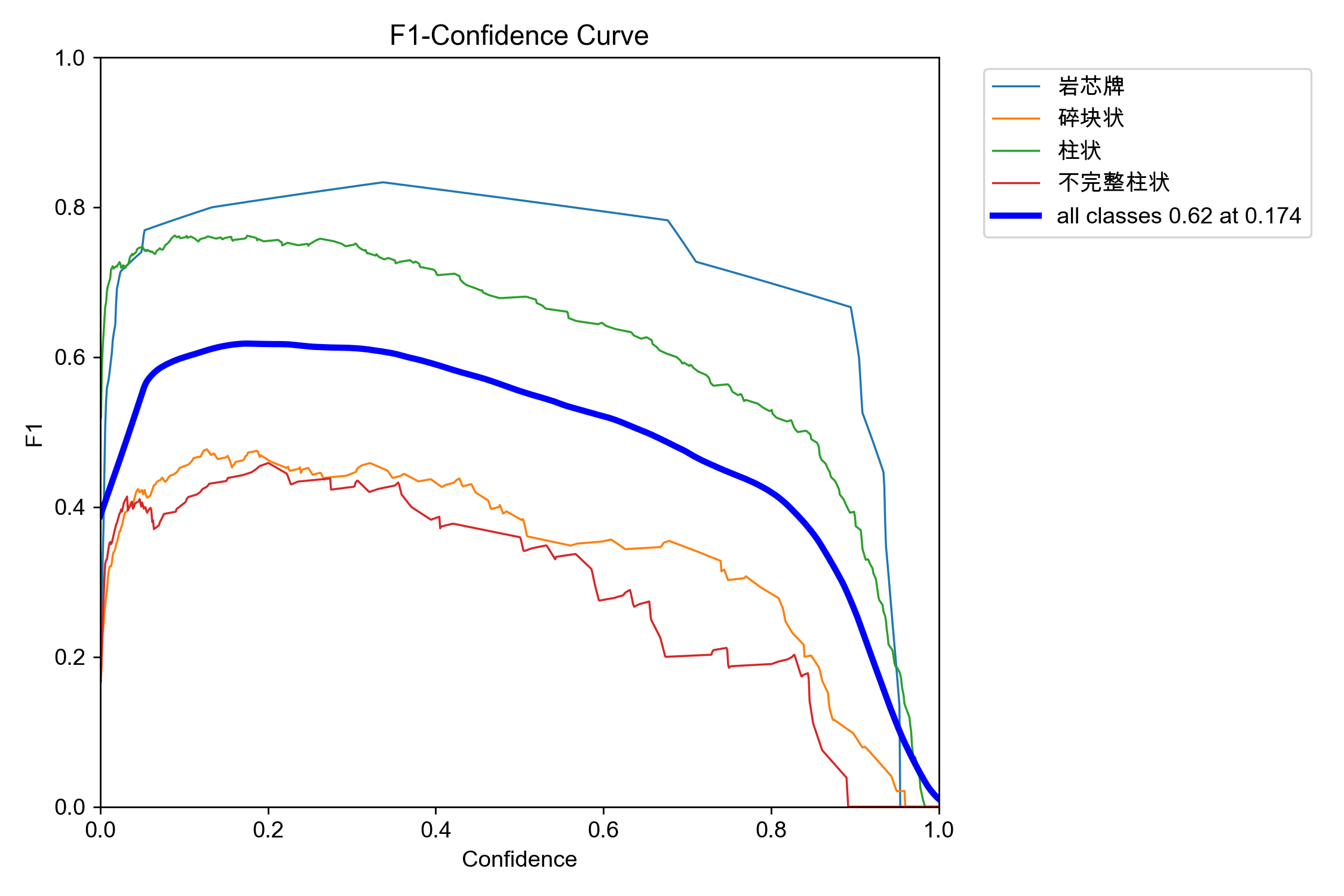
-
横轴(X轴):Confidence(置信度阈值,从 0 到 1)。也就是写代码时可以控制的那个阀门。
-
纵轴(Y轴):F1-Score(综合得分,从 0 到 1)。越高越好。
完美的 F1 曲线应该像一座高耸的山峰。山峰的最高点(波峰),对应的横坐标(Confidence),就是当前模型最完美的黄金平衡点。 也就是对照这个图,代码设置 conf=0.174 时,实力最强
深度调优
现状:看【岩芯牌】(蓝线)和【柱状】(绿线):它们的山峰非常明显,且波峰很宽,在 conf 处于 0.1 到 0.7 之间时,F1 得分都能维持在 0.7 以上的高位。这说明模型对这两个类极其自信,怎么设阈值它都不容易崩。
看【碎块状】(橘线)和【不完整柱状】(红线):它们根本没有山峰,是一条低平的矮丘。 在 conf 超过 0.4 之后,红线和橘线呈现陡坡式下滑。这种“塌陷且短命”的曲线,代表模型对这两个类别极度不自信。AI 即使认出了碎块,打出的置信度分数也普遍非常低
针对性调优动作:
-
调整分类损失权重(Cls Gain):在 YOLO 的训练配置文件(如
default.yaml)中,找到cls的权重参数(通常是cls: 0.5),尝试将其调大到cls: 1.0或更高。这是在口头上警告网络:“认错类别或者不敢认类别的惩罚加倍!”强迫网络在遇到破碎特征时提高自信心,把它们的置信度整体往右推。 -
检查边界标签:碎块和不完整柱状往往成片出现。检查是不是在标注时,有些碎块太碎了,标注员漏标了,或者直接把一整箱碎块当成了背景。这种“一会儿要学,一会儿又是背景”的混乱信号,是导致模型不自信的罪魁祸首。
4.Precision/Recall-Confidence 曲线 —— 研判极限能力
1. Precision-Confidence 曲线 —— 诊断“AI 信心上限与虚警”
核心读图逻辑:随着横轴置信度(Confidence)从 0 提到 1,AI 的胆子越来越小,只有极度有把握的目标才敢框出来,因此纵轴的精准率(Precision)整体趋势必然是一路向上扬,直到接近 1.0(100% 抓对)。
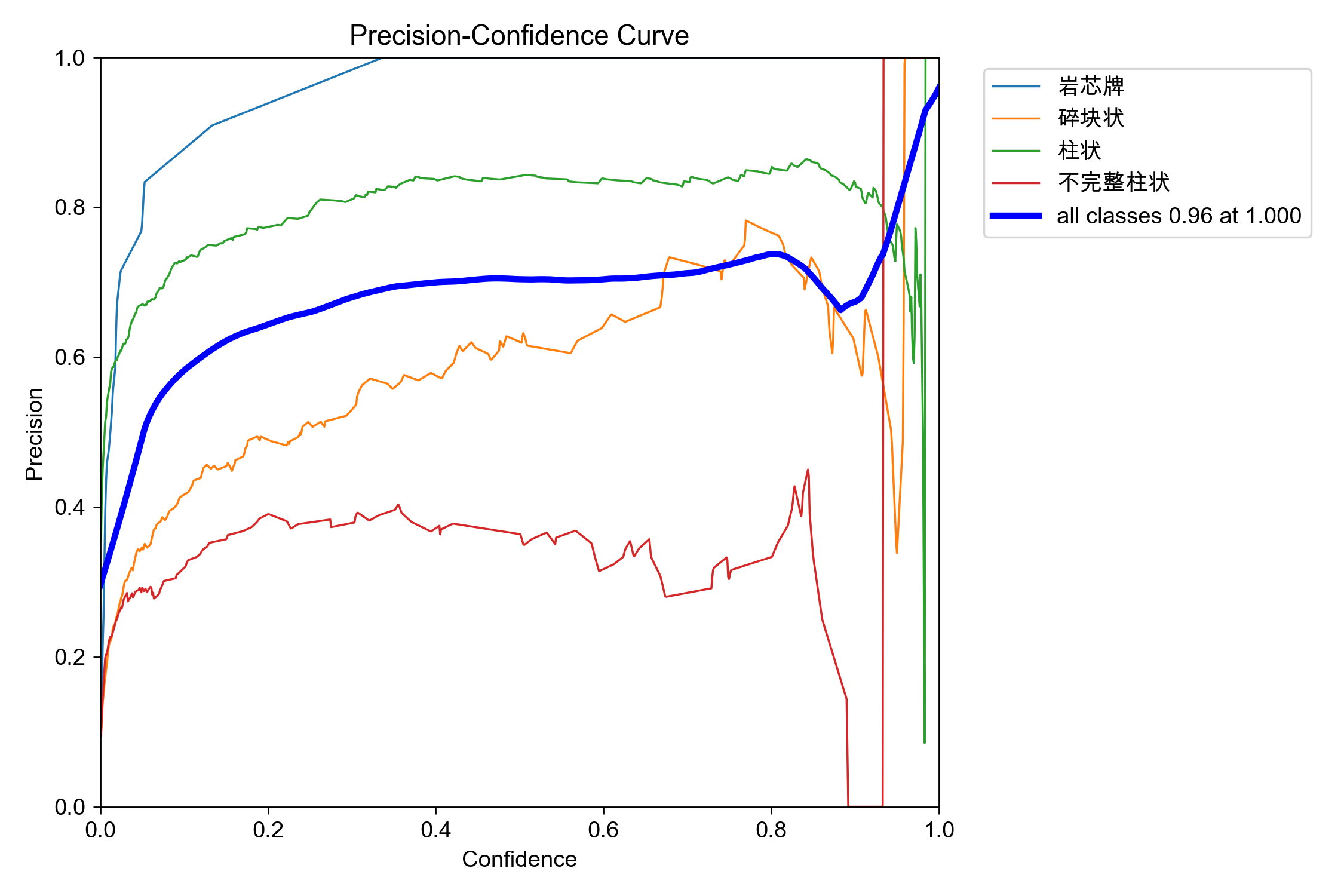
调优指导
- 诡异的异常点:【不完整柱状】(红线)在 0.89 置信度处直接坠落归零
- 现象:别的线在置信度接近 1.0 时都冲向了最高点,唯独红线在 0.89 之后突然垂直断档、直接归零。
- 病因分析:这并不是说 AI 在高置信度时变蠢了,而是AI 对【不完整柱状】这个类别打出的最高信任分,只有 0.89。
- 当你把代码阈值设到 0.90 时,AI 因为极度不自信,对这个类别吐不出任何一个预测框。在数学计算中,因为预测数量(分母)为 0,导致该类的 Precision 直接崩塌。
- 💡 具体的调优指导动作:
- 这再次证明你不能盲目提高部署时的
conf阈值。如果业务要求精准率达到 90% 以上,你盲目把总阈值切到 0.9,【不完整柱状】这个类在生产线上就会完全瘫痪(检测输出为 0)。 - 反思特征重叠:AI 为什么最高只敢打 0.89 分?说明在 AI 眼里,最完美的“不完整柱状”也长得有点像“碎块状”或“完整柱状”。在数据层面,需要补充那些特征极度典型、毫无争议的【不完整柱状】标准样板,强行拓宽它的信心上限。
- 这再次证明你不能盲目提高部署时的
2.Recall-Confidence 曲线 —— 诊断“硬性漏检与网络天花板”
核心读图逻辑:随着横轴置信度(Confidence)从 0 提到 1,AI 门槛变高,敢画的框越来越少,漏检必然越来越多,因此召回率(Recall)整体趋势必然是一路向下滑落。
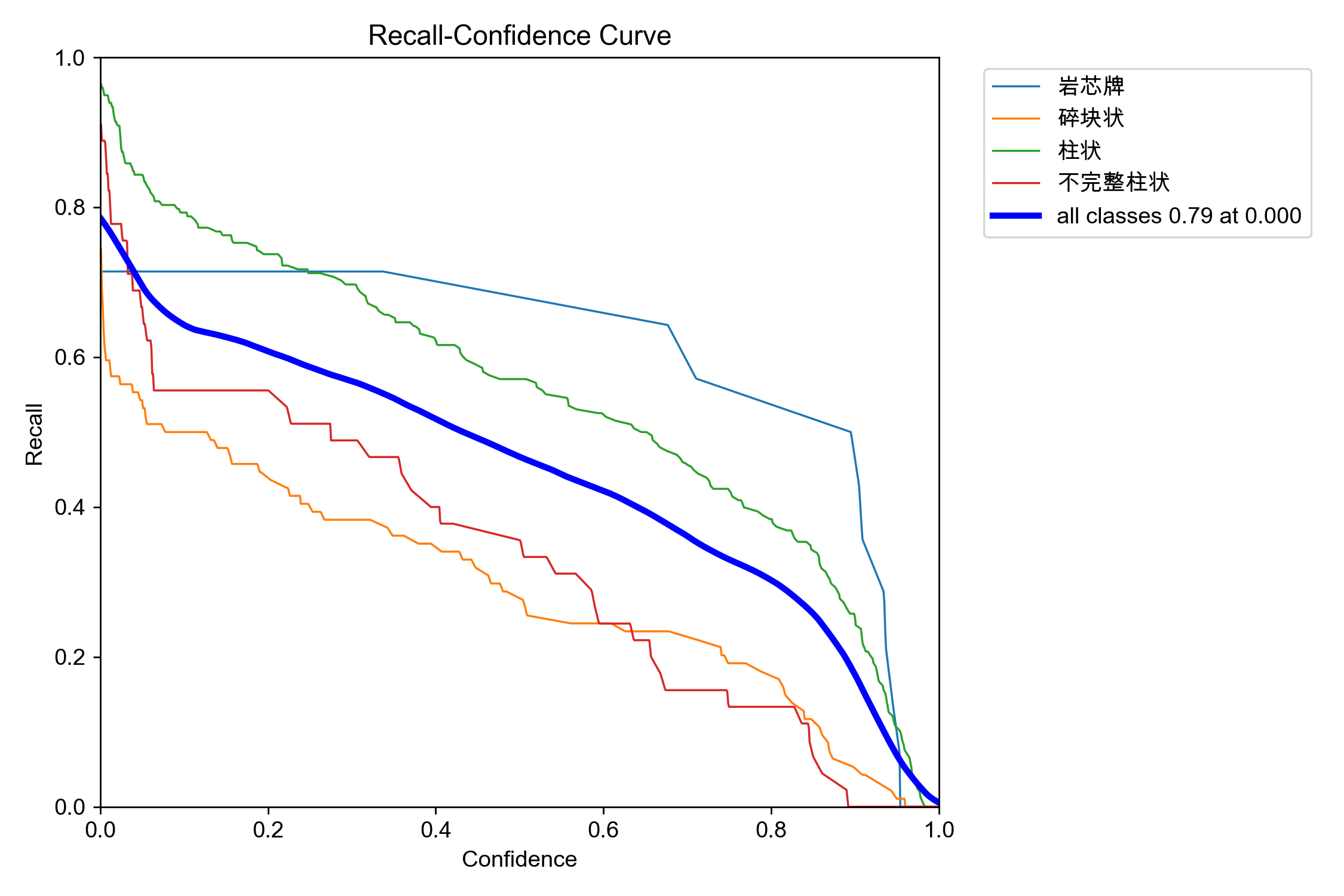
- 终极核心观察点:看横轴为 0.000 时的纵轴截距
- 你的数据现状:你的图里明确写着
all classes 0.79 at 0.000。 - 物理含义:当置信度阈值设为 0(即 AI 完全不设防,哪怕有 0.001% 的可能性也把框画出来,宁错杀一千不放过一个),模型也只能抓到验证集里 79% 的目标。剩下的 21% 目标遭遇了硬性漏检。
- 💡 具体的调优指导动作:
这是一个极其重要的分水岭信号!它告诉你:当前这个网络的底层架构,已经接触到了容纳能力的极限天花板。
- 不要再做无谓的调参:如果无论怎么放开限制,都有 21% 的岩心死活找不到,说明不是“阈值设错了”或者“分类没学好”,而是这 21% 的目标在网络进行特征提取(Downsampling 下采样的像素蒸发)时,特征已经彻底丢失了。
- 唯一的出路是改硬件或改模型大号:
- 检查打标签时,是不是有大量微小的碎屑被你打了标,而 1280 的分辨率下这些碎屑已经缩到了几个像素大小,s 号网络根本无能为力。
- 如果这些硬性漏检的目标很重要,下一轮必须断开断点,放弃 s 号模型,直接开一台物理机更换为
yolov26m或yolov26l进行大网络压制。只有更宽、更深的通道,才能在底层保住这 21% 丢失的像素特征。
- 你的数据现状:你的图里明确写着
数据集分析与可视化对比
最直观的debug工具
labels.jpg —— 数据分布的“透视图”
在开跑训练前,AI 必须先对你的标签数据进行一次“人口普查”。
也就是labels.jpg ,它由 4 张子图拼接而成,分别统计了:
1.类别数量条形图
记录了标签总数量
- 调优 如果条形图里【柱状】有几千个,而【碎块状】只有几十个,AI 就会产生“严重的分布偏见”,倾向于把一切都认成柱状。
2. 中心点散点图(通常标记为 x, y)
- 看图方法:横轴是目标中心点的 X 坐标,纵轴是 Y 坐标。图上的每一个蓝点,代表一个岩心目标的几何中心。
- 指导调优:
- 如果蓝点全密密麻麻堆在正中央((0.5, 0.5) 附近):说明岩心全是在画面正中间拍的,四周全是空白。AI 长期学这种数据会变懒,一旦实际生产中岩心偏到了画面边缘,它就认不出来了。
- 对应动作:在代码配置中调大
translate参数(位移数据增强,比如translate: 0.2),强迫模型在训练时把图像往四周拽,打破这种位置偏见。
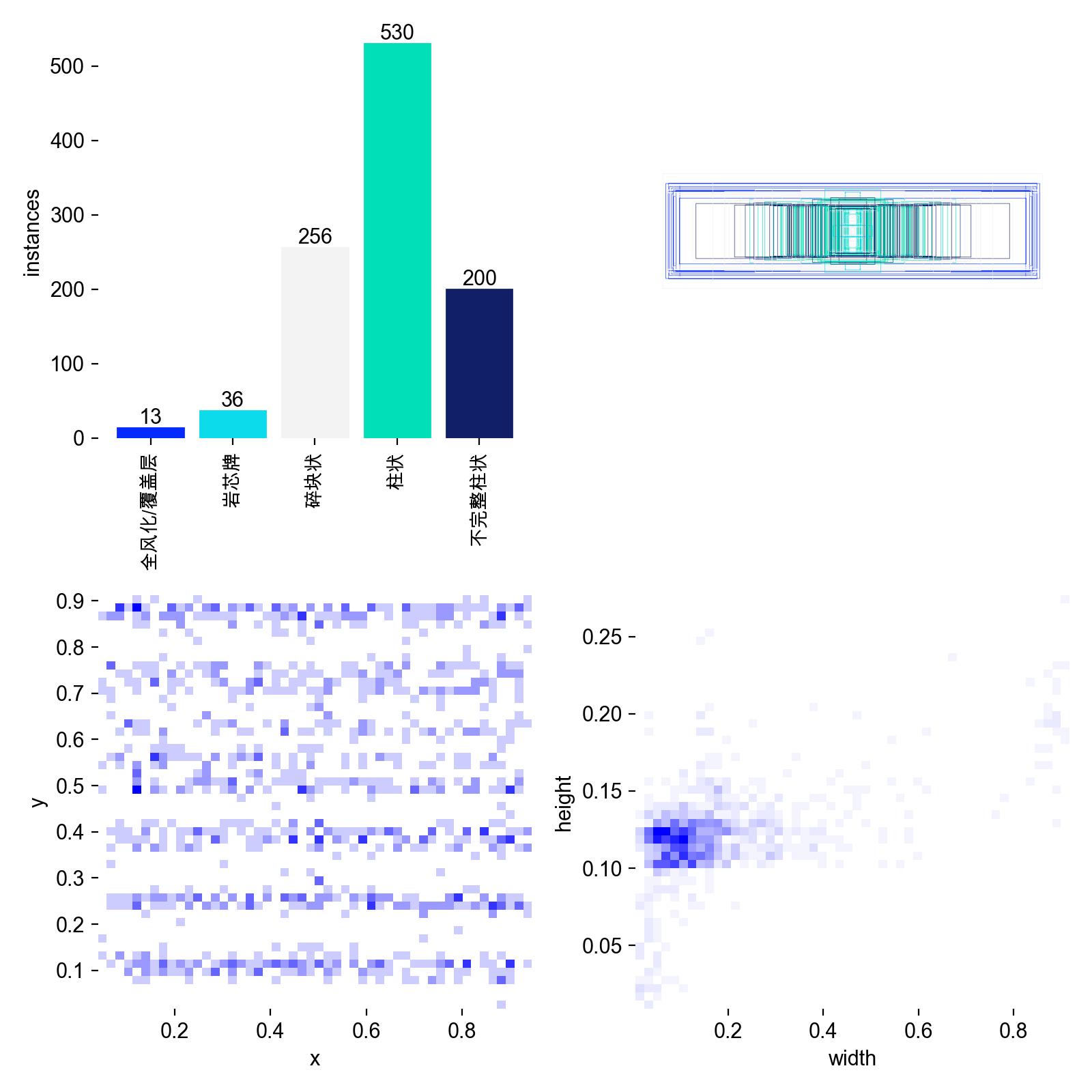
2. 宽高尺寸散点图(通常标记为 width, height)
- 看图方法:横轴是目标的相对宽度,纵轴是相对高度。
- 指导调优:
- 如果所有点都死死挤在左下角(接近 (0, 0) 区域):说明数据集中,绝大多数目标的像素占比都极小(比如微小的破碎岩心)。
- 对应动作:这直接决定了能用普通的 640 分辨率,必须死守
1280甚至更高的分辨率。同时,如果下一轮你想换大网络,它能指导你是否需要调整多尺度训练(multi_scale=True),让网络在训练时动态缩放图片,提高对极端尺寸的适应力。
3. 边界框叠加热力图
- 看图方法:把成千上万个矩形框的左上角全部对齐到 (0,0) 坐标,然后层层叠加,颜色越深代表框的尺寸出现频率越高。
- 指导调优:
- 它能一眼看出你的岩心大多是长条状(柱状)还是方块状(碎块)。如果岩心全是细长条,但热力图显示有很多正方形的框,说明有些长条岩心被标注员切成了好几段来标,存在标注逻辑不统一。
train_batch0/1/2.jpg —— 模型眼中的“魔改现场”
为了让AI 的生存能力更强,他自己会先增强一下输入训练数据,YOLO 在后台会对图片进行极为残暴的“数据增强”:把 4 张图强行拼接(Mosaic 增强)、随机裁剪、翻转、变色、加噪点等。train_batchX.jpg 就是 YOLO 把拼好、洗好、改好的图片,在真正塞进网络前的那一瞬间,截了一张图。 上面还会自带你画的绿色分割标签。
这个一般不会出错,可以检查一下输入增强图符不符合规范有没有出错,比如发现由于 mosaic(马赛克拼接)算法太剧烈,把原本好端端的【不完整柱状岩心】给切得稀碎,在画面里变得像【碎块状】一样,这就破坏原始标注了。
val_batchX_labels.jpg VS val_batchX_pred.jpg —— 考卷与标准答案对账 *
- 调优指导: * 排查假虚警:若 Pred 中检出了标签中漏标的真实岩心,说明数据存在漏标 启动数据清洗,补齐标签。 * 排查误检源:观察误检掩膜(Mask)的物理位置。若高发于木隔板或箱体阴影,说明背景区分度不足 往训练集中移入不带任何标签的空箱“负样本(Background Images)”,强制压制背景幻觉。