6.05
预训练数据
- 裁剪前期标注素材
- 标注了40张图
训练
- 使用yolo26s-seg.pt进行fine-tune 微调,把已有视觉能力迁移到岩芯场景
- 使用了32张训练集,8张作为评估验证集
- 先训练了300epochs
- 尺寸是1280,因为是长图,高度会自动padding,可能后期为了更好的分辨率精度,需要看看怎么裁剪
训练过程
前 78 轮(粗略定位阶段):模型快速学会了“目标大致在哪里”、“轮廓粗略是怎样的”。所以在宽松的 50% IoU 阈值下,它在 78 轮mAP50就拿到了最高分。
78 到 194 轮(边缘精雕细琢阶段):在此之后的 100 多轮里,模型的整体检出能力(mAP50)没有太大的绝对提升,甚至可能因为轻微波动还掉了一点点,但是它在把 Mask 的边缘扣得更准、更精细。高严格度阈值(如 IoU 0.85、0.90、0.95)下的得分一直在持续上涨,最终把平均分 mAP50-95 推向了 194 轮的最高点。
最佳跑了 epoch 194 Mask mAP50-95 = 0.45836
mAP50 (0.548) 和 mAP50-95 (0.458) 之间的差距非常窄(仅有约 0.09)。 说明只要模型成功把这个物体认出来了,它吐出来的 Mask 边缘就和真实标签贴合得极其精准。

瓶颈
岩芯牌 Mask mAP50-95 0.640 碎块状 Mask mAP50-95 0.248 柱状 Mask mAP50-95 0.705 不完整柱状 Mask mAP50-95 0.205
总宽松指标 Mask mAP50 卡在了 0.548
也就是,碎块状、不完整柱状、碎块状 vs 不完整柱状 vs 柱状 的边界问题比较明显
一句话总结:目前类别边界不稳定、碎块状/不完整柱状样本和标注粒度不够支撑精细实例分割
后续优化
1.通过分析混淆矩阵,标签会出现19%左右的混乱,pr曲线的碎块状和不完整柱状,Recall召回剧烈震荡下滑,说明这两个特征基本处于懵逼状态(因为我标记的时候确实也懵逼),说明需要标注时候在仔细确定一下类别,统一一下或者标签大类合并一下;
2.很多碎块状有36%变成了背景,这个也有标记的原因,当时用了一个大 mask 粗覆盖一堆碎块 漏掉小碎块,可能就有小碎块边缘并入柱状或背景,导致小碎块也可能有了背景的含义。 需要增加空箱负面样本,以及调大cls损失权重,漏检惩罚更厉害
3.分析pr曲线和r曲线,平均精度在0.5,以及21%岩芯丢失,限制是在分割头上,就是Backbone特征提取网络和检测头下采样像素没了,特征完全丢失,需要用更大尺寸的底模;
4.素材局部增强,可以单独把局部弄出来看,不只是看大轮廓;yolo默认会使用 方图,方便对齐四维张量。现在可以开启矩阵训练,整箱图可以考虑切成多个重叠crop,每个crop单独预测,把预测 mask 坐标映射回原图,合并结果
5.隐患,pr曲线和labels图的样本分布不均衡厉害,pr图的柱状有0.774面积,其他碎块状(不完整柱状)分到了0.38,覆盖层几乎没有了;labels图的柱状标签有530个,需要增加对应标签样本, 达到不同效应,否则总分上不去,被拖累
使用更大尺寸底模,图片预处理,训练使用更大分辨率
6.12
优化训练集
- 将 不完整柱状和碎石块合并
- 使用无 padding 的方图 crop 数据集
二次训练
岩芯牌: Mask mAP50-95 约 0.741
碎块状: Mask mAP50-95 约 0.317
柱状: Mask mAP50-95 约 0.849
最佳轮次,epoch 279 Box mAP50-95 = 0.66355
可能原因
合并后类别内部形态跨度变大:小碎块、大块、不完整柱状都进了同一类,类内差异变大,碎块状更像一个“大杂类”。 碎块状边界天然不规则,mask 标注一致性比柱状差。 但合并后下一步要做的是提高这个大类的样本覆盖
优化方案
1.补碎块状困难样本 重点补:小碎块、浅色碎块、贴近箱底颜色的碎块、边缘被裁断的碎块、碎块和柱状混在一起的样本。2. 提高碎块状标注一致性,碎块状有的按整堆圈,有的按单块圈。这个会严重拉低 mask mAP95。
换框架训练
-
尝试使用Mask2Former模型框架方案,搭配swim-B进行训练尝试
-
服务器配置训练框架
-
训练了3300 iter,最好的是iter_2310,1.2G
-
segm_mAP_50 0.605,segm_mAP_75 0.414


6.20
训练
-
更换骨干网络,抛弃了CNN,使用 DINOv2作为骨干网络用来提取特征。
-
DINOv2是SAM2的骨干,数据量大,训练了30张素材,用了36个小时
-
使用RF-DETR框架进行颈部的特征提取,以及编码和解码的部分;抛弃了之前的transformer编解码,但是类似transform,他是内部维护了一组专门的嵌入向量Q,用Q去寻找对应实例,
-
74轮训练出最佳,但是跑完了250轮36个小时 segm_mAP_50_95 = 0.7484 segm_mAP_50 = 0.8474
全风化/覆盖层: AP 0.9356,
岩芯牌: AP 0.8086,
柱状: AP 0.7661,
碎块状: AP 0.3351
- 但是效果已经能用了
岩芯计算
“有效轴向长度”算法设计
-
不能按照X方向来算,有一些斜放的就不准了
-
PCA 找到一条横向主轴,也就是岩芯大体从左到右的轴线
-
沿着主轴每5像素切一刀
-
切出来的每一小段都量一下“垂直于岩芯方向的截面宽度”,大于75%正常宽度视为正常。
-
找出截面宽度接近正常岩芯宽度的连续区间,是否大于10cm。
-
有效长度 = 去掉最左 5% 噪声、最右 5% 噪声以后,中间稳定部分的长度
现在按遮罩点集的主方向 PCA 投影来算:
最大长度:主轴方向上的完整投影长度;最短长度:去掉两端 5% 噪声后的有效主轴长度;合格(≥10cm):按这个有效主轴长度判断。
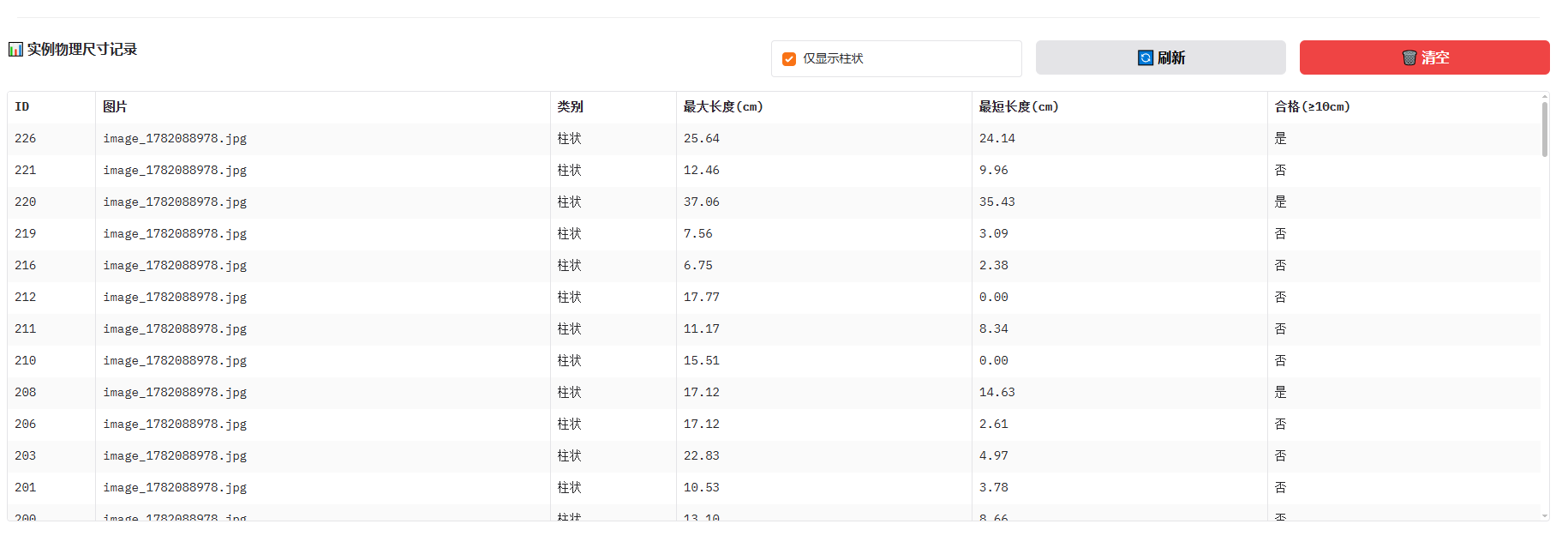
6.29
规范库讨论
-
部署百度的ocr
-
制作一个判断文档是否需要ocr的便携包,使用pypdf库调取前几页,调用
get_text()会返回大量的文本字符,如果没有字符串就是扫描图片件,需要ocr。 -
讨论怎么接入
-
对接好了S3的文件管理,现在可以文件同步了
探索岩芯照片转为3d岩芯柱
去调研查看开源的图片编辑模型
调研图片生成3d的大模型
下载了几个,部署实时,