4.03
实体抽取
测试
- 将文档格式化+约束schema汇总——大模型——返回实体+证据+关系
- 测试先格式化信息传入,结果只抽取了400实体,输出预算也很紧,模型一轮里既要抽实体,又要补证据、抽关系,负担太重,实体召回上不去。
现在方案
- 长文档按章节切大段,不碎片化
- 分段只做高召回实体
- 证据和关系后置到全局阶段
1.document_reader
把原始 Word/PDF 解析成规范化全文包 reading_pack。保留全文段落、章节目录、表格、图题、编号和定位信息,作为系统内部标准输入。
2.segment_builder
针对超长文档,按“章节边界 + 长度上限”切成 3 段左右的大段,尽量保持章节完整
3.segment_context_builder
为第 2、3 段生成“受控桥接摘要”。摘要只继承前段核心实体和必要上下文,不允许引入新事实,作用是保持跨段连续性。
4.segment_extractor
每个分段只做第一轮“高召回实体候选抽取”,不在这一轮强行抽属性、关系和完整证据,先把实体数拉起来。
5.segment_merge
把多段实体结果合并、去重、别名归一,形成全局实体池。
6.global_evidence
基于全篇和全局实体池,统一补证据。为了稳定性,证据轮按批次执行,避免一次性给几百个实体补证据导致输出失控。
7.global_relations
在全局实体池上统一抽关系。关系不在分段阶段做,避免局部视角影响全局判断。
8. review_html
最终把 reading / entities / evidence / relations 生成为一个审查 HTML,方便人工核查,而不是直接看一堆 JSON。
-
结合schema,汇总为大模型的输入
-
新增用户管理功能,以及管理员可以给普通用户开通公共库的权限
-
普通用户沿用统一的admin用户的模型部署
后续
- 关系覆盖率提升
- type_guess 向固定 schema 收敛
- 再往后就是 SQLite 落库和服务化接口
4.13
筛选和数据写入
- 使用schema初步筛选,从前一次跑的300多个实体进行筛选,得到了152实体,181证据和23关系
- 写入到SQLite,并转化未json
接入前端
- 将数据接入前端测试
- 修改为只是图形点和关系图两种模式,点击可出现属性
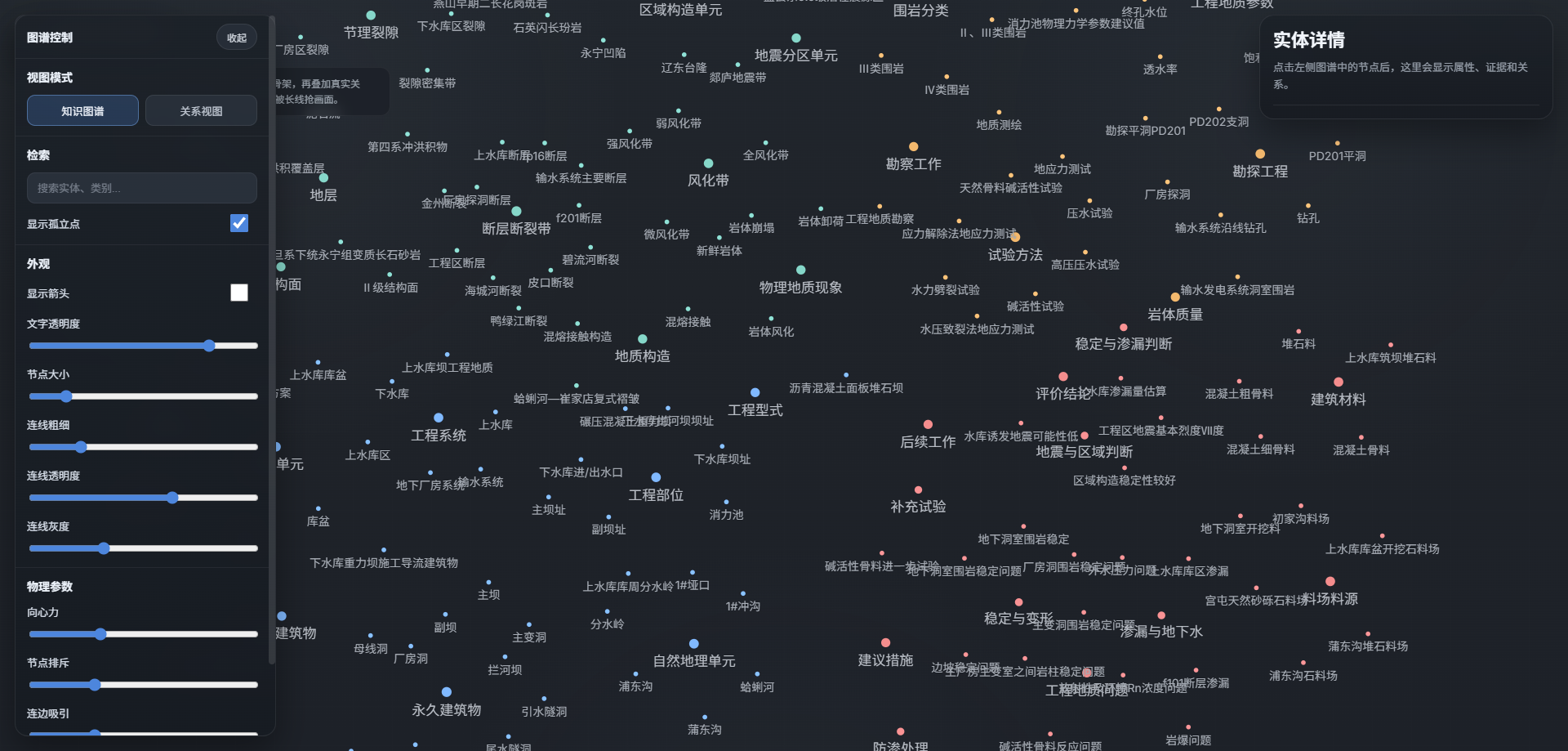
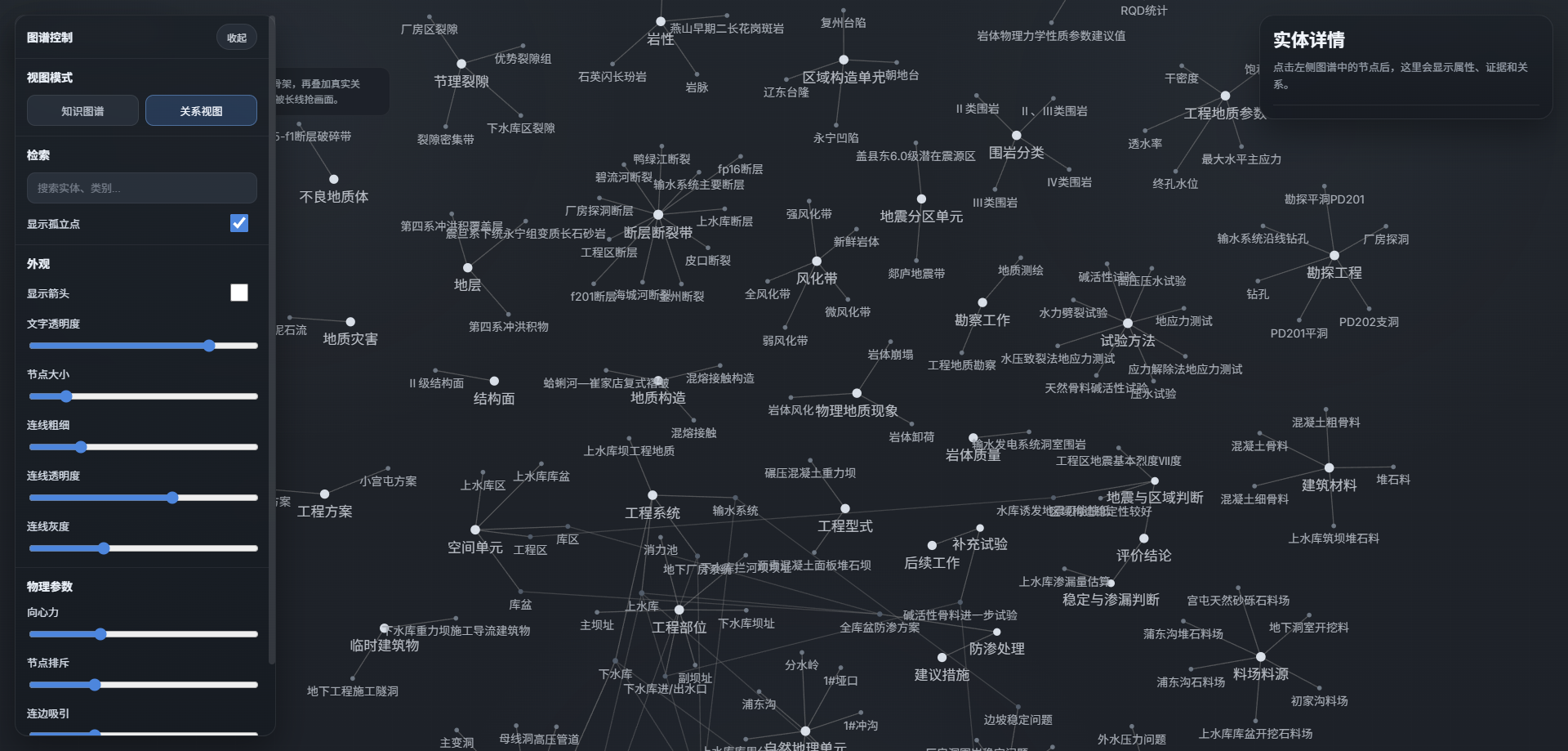
加一个证据回溯超链接可以回溯跳转到具体章节片段
4.17
优化请求次数
- 减少叶子节点,大约21万字文档收缩到请求15次
- 按照段落分出大概是哪段schema,然后在去拼接payload
- 细分段落 + schema约束 + JSON输出约束
- 新增合并脚本,合并别名、属性、证据、来源段落
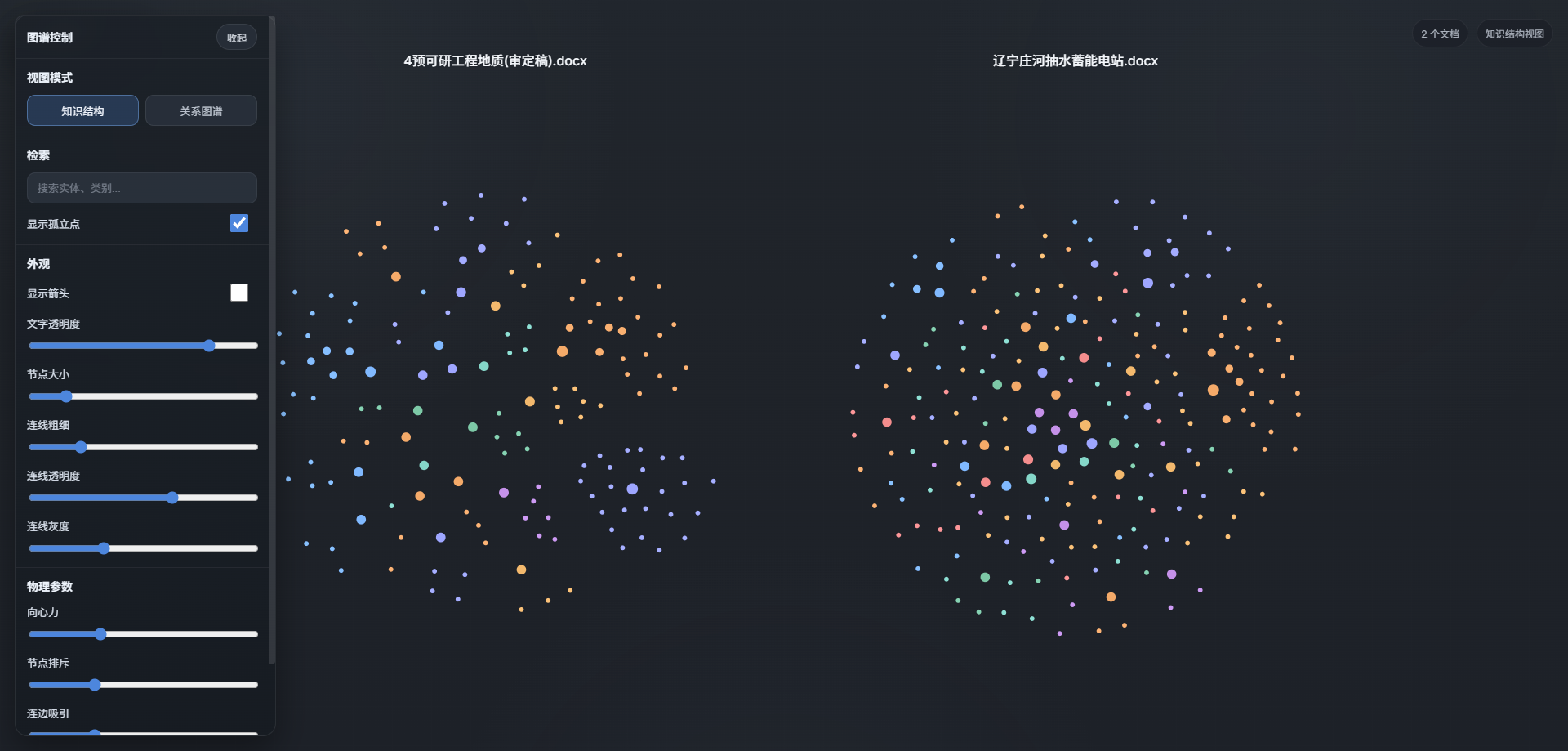
按知识库提取
- 按知识库,多文档去抽取实体
- 前端多文档共同展示实体
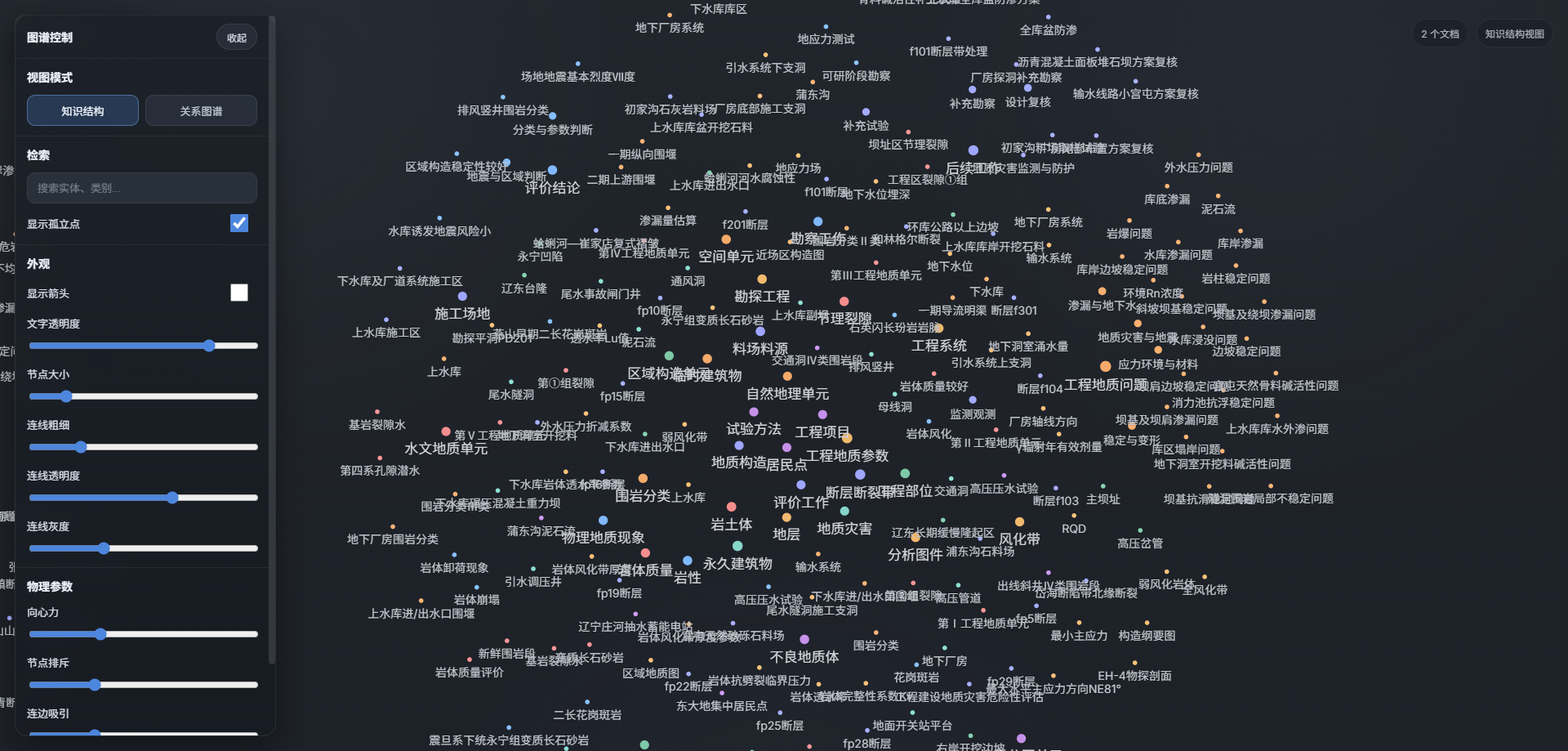
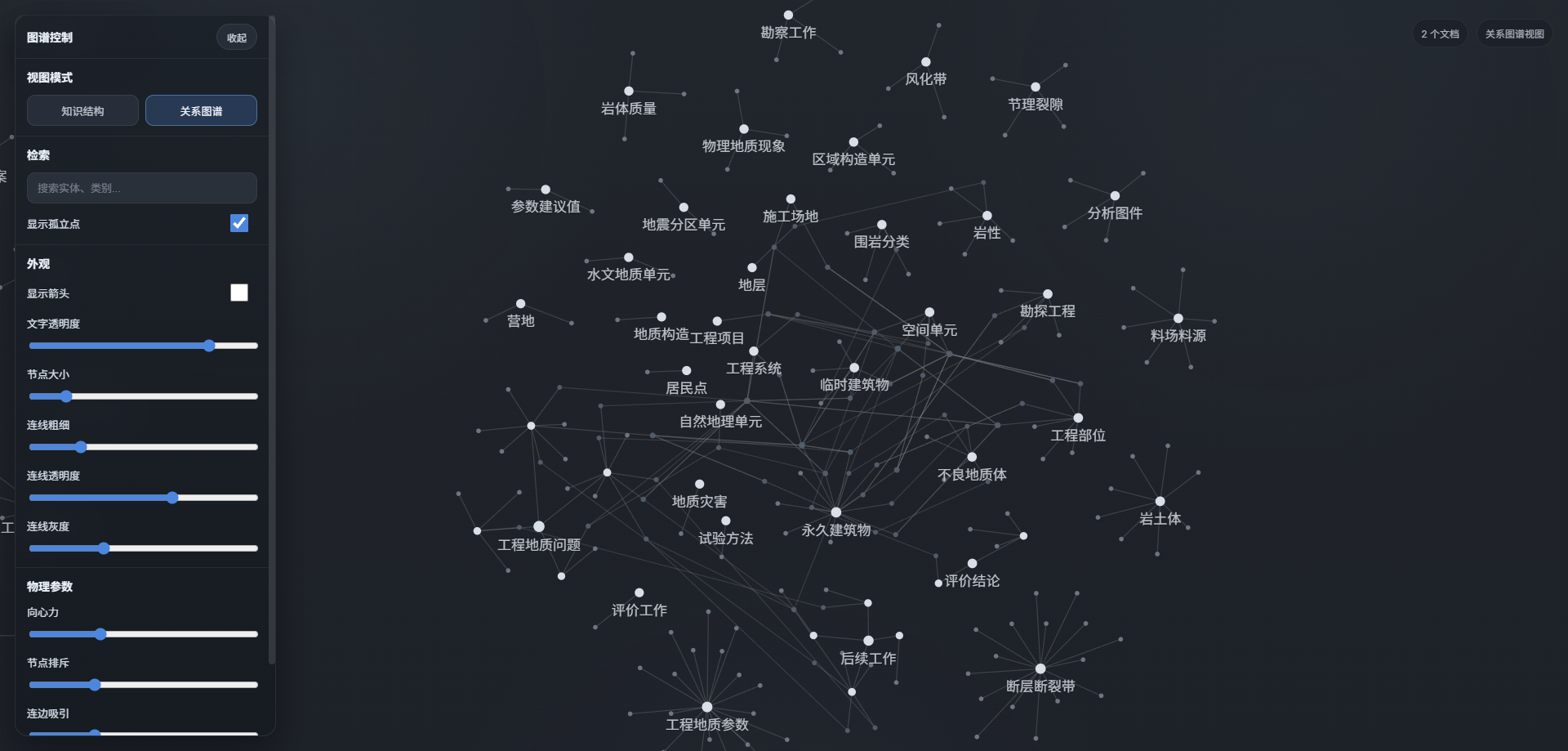
4.25
新增前后端独立执行程序
- 前端页面打开时候,默认列举出知识库列表,选择加载对应知识库实体
- 新增后端抽取实体独立程序
- 新增后端约束规则网页端配置UI
打通知识库+知识图谱
- 把知识图谱的前端已经接入到知识库里面去了
- 接入抽取知识库实体的后端服务