10.17
尝试开始知识库的流程
- 通过知识库关键字,延伸出关键字 RAG,开始学习RAG基础知识
- 通RAG了解到了几款开源工具,anythingLLM、RAGFlow、langflow、dify
- 利用ollama搭建本地语言大模型,千问3 8B以及DeepSeekR1-8B,嵌入模型BAAI
- 通过几款开源工具搭建试用,了解到了两个方面,(1)RAG的局限性(2)各种RAG类型RAG局限性
尝试更高级的知识库
- 加入重排器,使用上下文压缩能力更高的API调用
- 搭建微软的GraphRAG试用,大概都能走通


10.24
写堆石坝开发文档
查看RAG服务源码框架
框架结构
数据清洗
新增了几个功能
- 单文件太大,主要是图片太多,已做 文档去除图片脚本
- BAAI/bga-m3不支持解析doc,doc、docx等转换为txt
向量化
数据检索
后台框架
测试的条件
- 都是内部或自己知道的知识,文档
- 除了语言全量大模型拿api,其他全部自己部署的,嵌入模型和重排模型使用本地的BAAI模型,排除不是本地的因素
- 连续发问,单窗口发文,包括测试上下文干扰问题
相对正确回答
地质报告测试
个人笔记测试
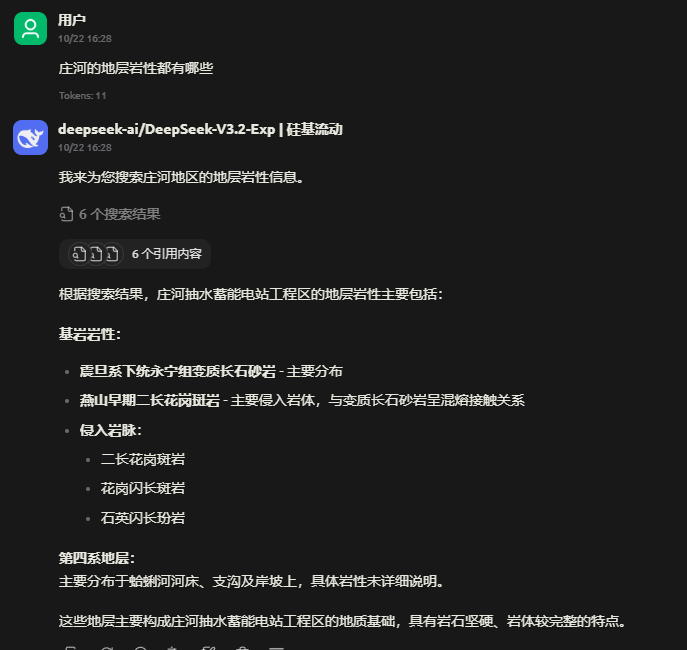
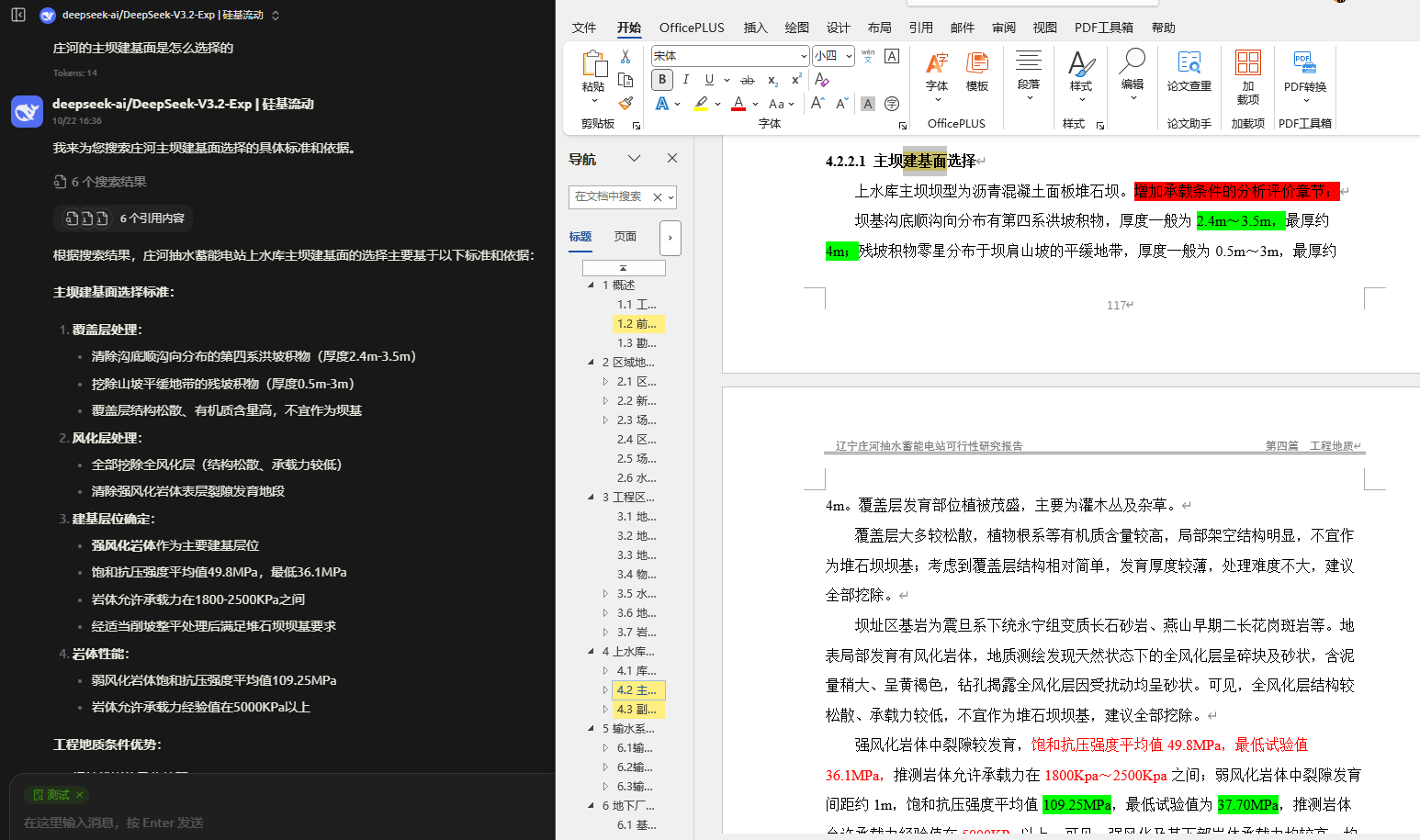
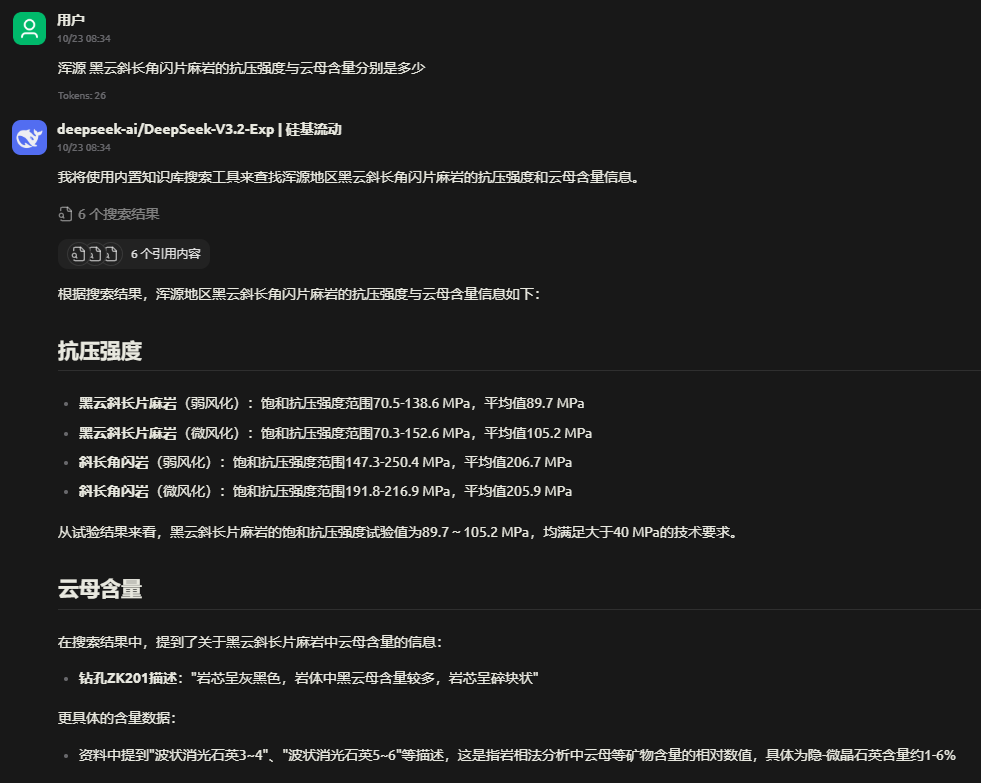
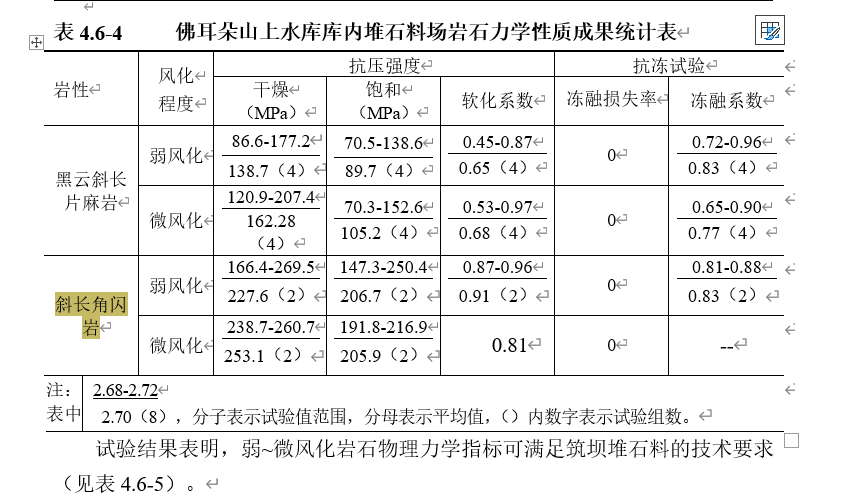
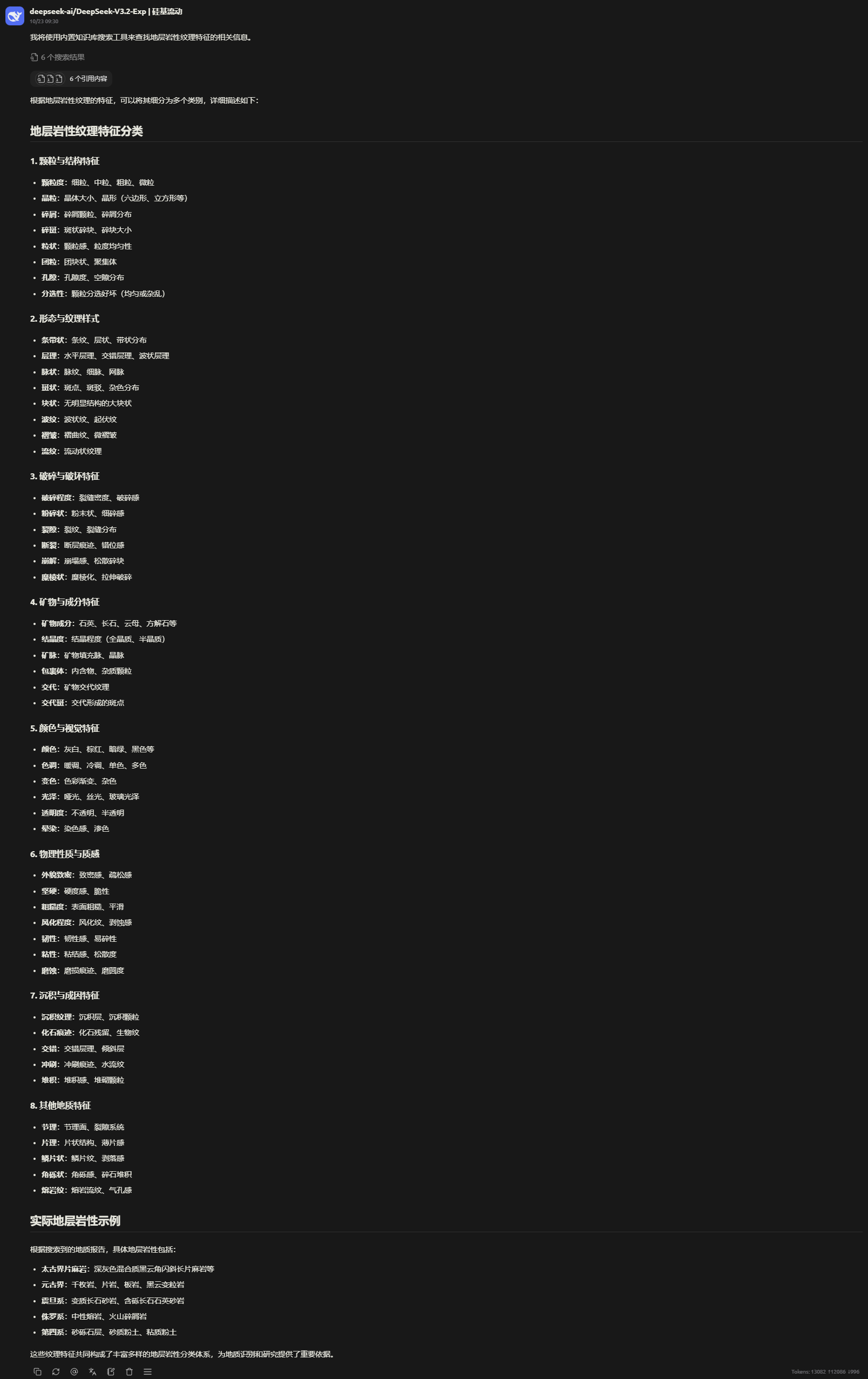
问题:地层岩性纹理都有哪些特征
PDF图文测试
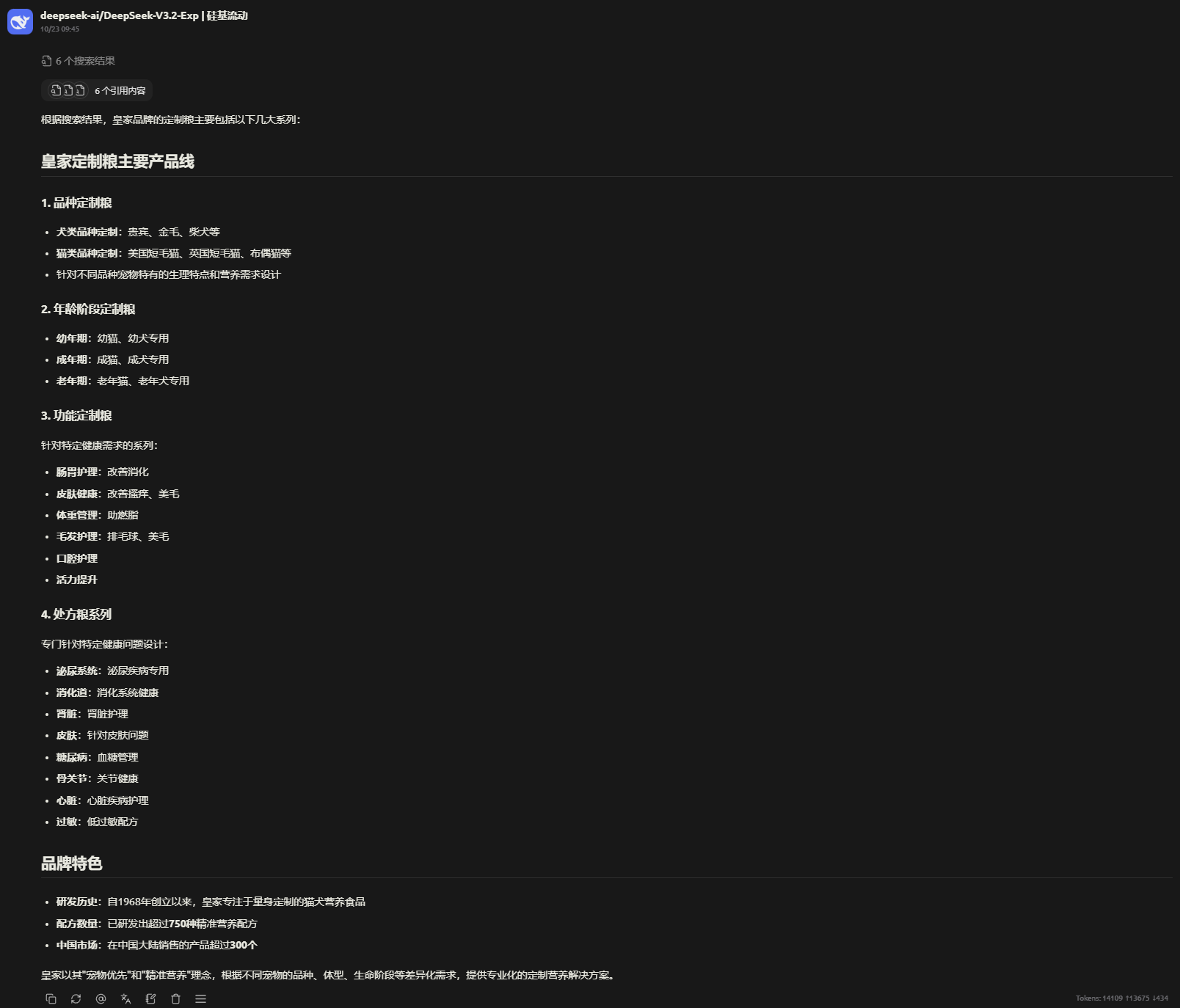
问题:皇家都有哪些定制粮
excel测试
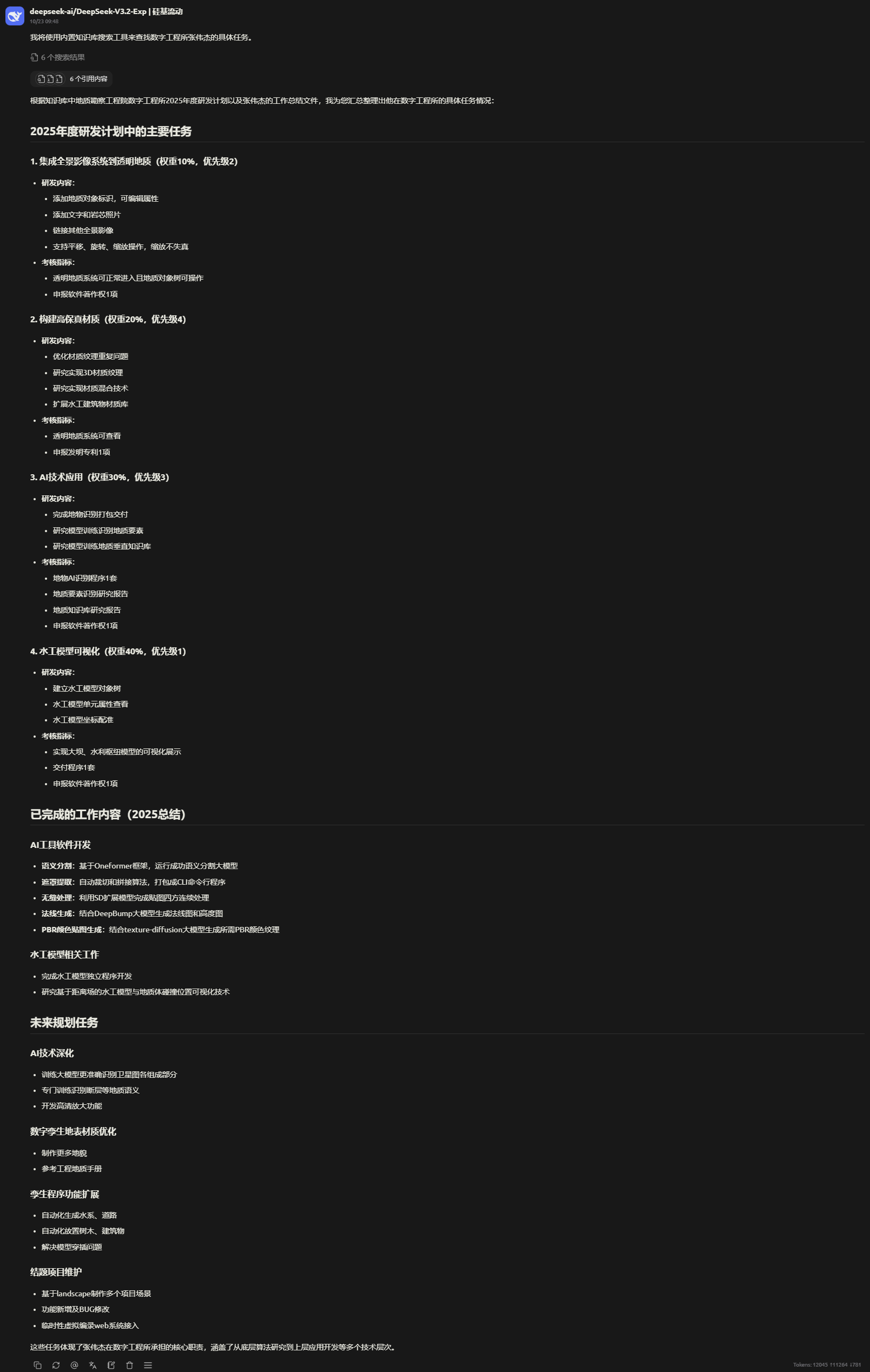
问题:张伟杰都有哪些任务
·
测试问题
- 召回问题偶尔有歧义,如全篇word只有文件名有一个浑源,其他全部没有浑源两字,再问浑源其他地方,会串到其他文档,所以适不适合知识图谱
- 地质文档自己本身就不准确,有可能在不同尺度名称不一样,有可能就是单纯写错
- 单窗口一直发问,偶尔会断掉知识库的链接,这是一个闭包(Closure)导致的状态缓存问题
- 冷启动后第一问走的是意图分析器的兜底逻辑,这个兜底流程目前不会自动重试,也不会把高质量 rewrite 缓存下来,所以冷启动后的第一问很容易“踩空”



10.31
透明地质修改bug
1.修复图片加载单通道导致道路变红的问题 2.打包后初始化进入场景不主动聚焦地面
知识库部署
- 替换应用图标、名称以及托盘
- 语言大模型问题,量化模型支持不好,服务器部署了千问3:30B,测试效果依旧不行,有可能是ollama的支持上下文限制了
- 必须要用全量,这样的话,API就需要考虑,现在用硅基流动,付费,还有安全问题,虽然本地向量数据库在本地,但是使用大模型能力会读到提示词里包含 文档的小片段内容
- http://10.216.186.24:8081
1. API Server 服务搭建
-
使用源码内置的 API Server(Express 框架)
-
测试 路由
/v1/chat/completions接口正常工作
2. Web 客户端开发
- 制作聊天界面 HTML,接入支持markdown的js库。
- 聊天为 Server-Sent Events (SSE) 流式传输,使用 TextDecoder 逐块解析数据,不然等待所有回复完毕统一加载会很慢,使用硅基流动得等30-60s,这样可以直接看到回复,像打字机一样
- 大模型调用,使用的是OpenAI的API规范,这样就兼容了市面大部分API格式
3. 知识库集成到 Web 端
问题发现
- Web 端调用 API Server 时,发现知识库搜索未生效,找到原因是API Server 绕过了知识库逻辑,直接转发到大模型
-
- http://localhost:8080/api-docs/ 并且没有关于知识库的任何接口
解决方案
-
在API Server中新增一个单独的知识库服务模块,去接受知识库配置,调用knowledgeBaseService.search()开始走知识库插件流程
-
添加 provider 自动识别逻辑,检测 URL 是 ollama 还是其他什么api,然后判断
/v1后缀是不是需要自动补全
4. 局域网多人访问部署
网络配置
-
修改 API Server 绑定地址:从
localhost改为0.0.0.0,这样监听所有网络接口, -
配置 Windows 防火墙规则(端口 8080、8081)
-
开了以上两个条件,局域网内其他电脑能访问
-
Web 客户端目前配置api地址、key,还有知识库id
下周计划
-
好像是解决了,但是好像还有一点点问题,再试试。重排器失效(冷启动问题),第一次提问回答不准确,热启动后第二遍回答正确,意图分析器的兜底逻辑在冷启动时未自动重试,需要预热,优化冷启动问题,改进意图分析器逻辑
-
考虑要不要添加 Web 端的知识库管理界面
-
找找有没有好用的mcp,能提升能力的
-
部署到服务器,然后完结